Release notes 25.3
HIGHLIGHTS
- Dataedo Browser Extension
- Import Metadata in Portal - Amazon Redshift, Azure SQL Database, MySQL, Oracle, PostgreSQL, Power BI Reports and Dashboards, Snowflake, SQL Server
- Data Quality - Configurable thresholds, Reusable rules, Rules on views, Bulk assignment of rules, Bulk threshold editing, Expanded rule suggestions, Unified metrics everywhere, New dashboard filters, Custom failed rows count for SQL rules, Operational Dashboard enhancements
- Scheduler - Delete data sources and connections in Portal, In progress task indicator, Deprecated connectors label
- Connectors - Improvements for Databricks, AWS Athena, Redshift, Power BI, SSRS, SSIS, SSAS Tabular, Snowflake Enterprise Lineage, PostgreSQL and MySQL.
- Dataedo Agent - New cross-platform application, New Windows installer
- Steward Hub - Foreign key suggestions, Interactive Data Quality suggestions
- UX/UI - Smarter navigation, Consistent layouts, Refreshed components, Filters in URLs
- Login - Email field synchronization for SAML, Default login method fix
- Other improvements - Task scheduling via Public API, New repository creation option in Portal
Dataedo Browser Extension
Now you can bring Dataedo right into your BI workflow with our new Browser Extension.
It allows you to see key catalog details (such as descriptions, glossary terms, owners, certification status, or lineage) directly inside your Power BI and Tableau dashboards. Thanks to this, you can better understand and trust your data without leaving the reports you’re working on.
This means less context switching and quicker insights, as all the critical business context is available exactly where you need it most.
Read the full guide in our documentation
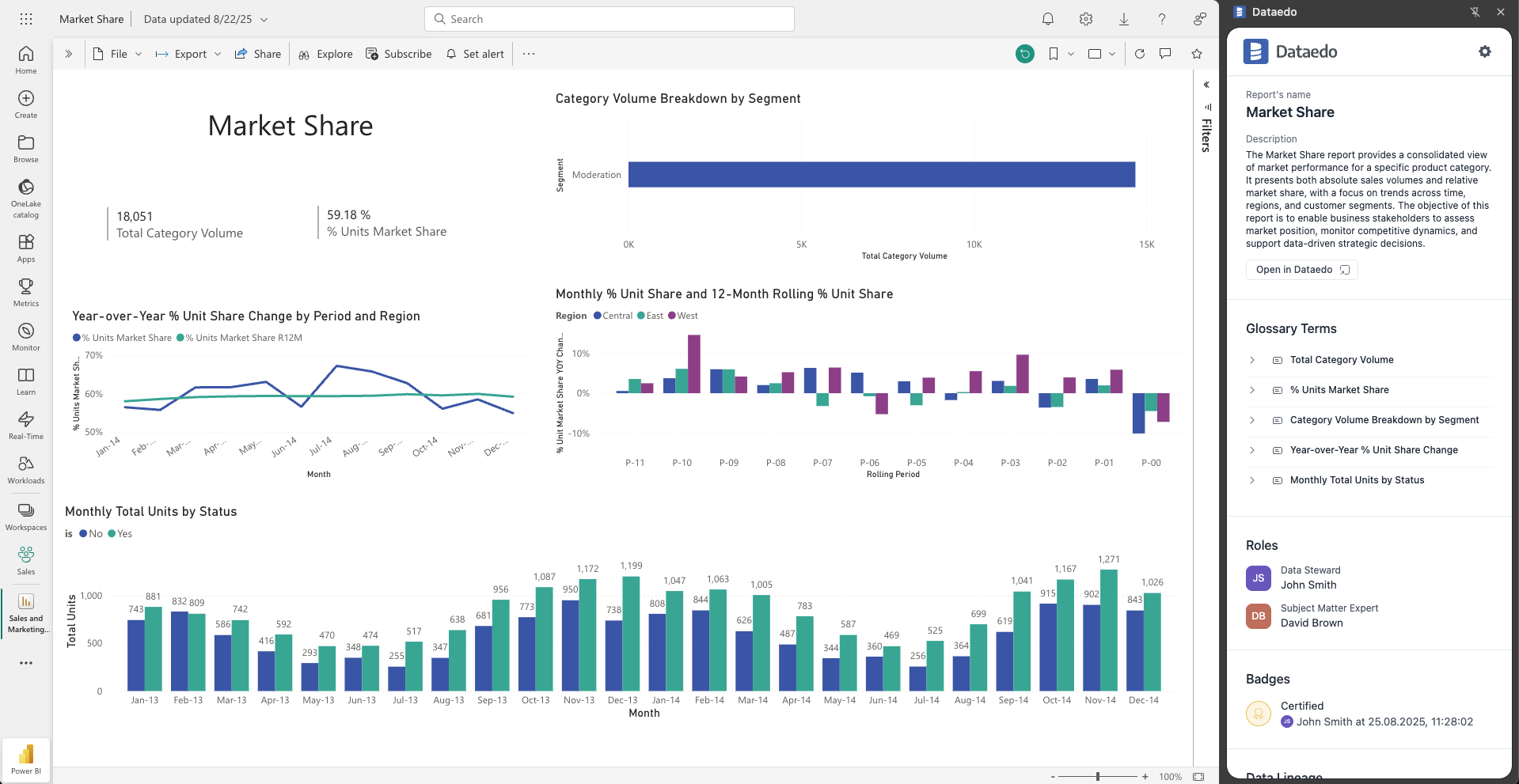
Import Metadata in Portal
Until now, metadata import was only available through Dataedo Desktop. Starting with this release, you can perform imports directly in the Portal – initially for a selected set of connectors:
- Amazon Redshift
- Azure SQL Database
- MySQL
- Oracle
- PostgreSQL
- Power BI Reports and Dashboards
- Snowflake
- SQL Server
Import multiple sources from one host
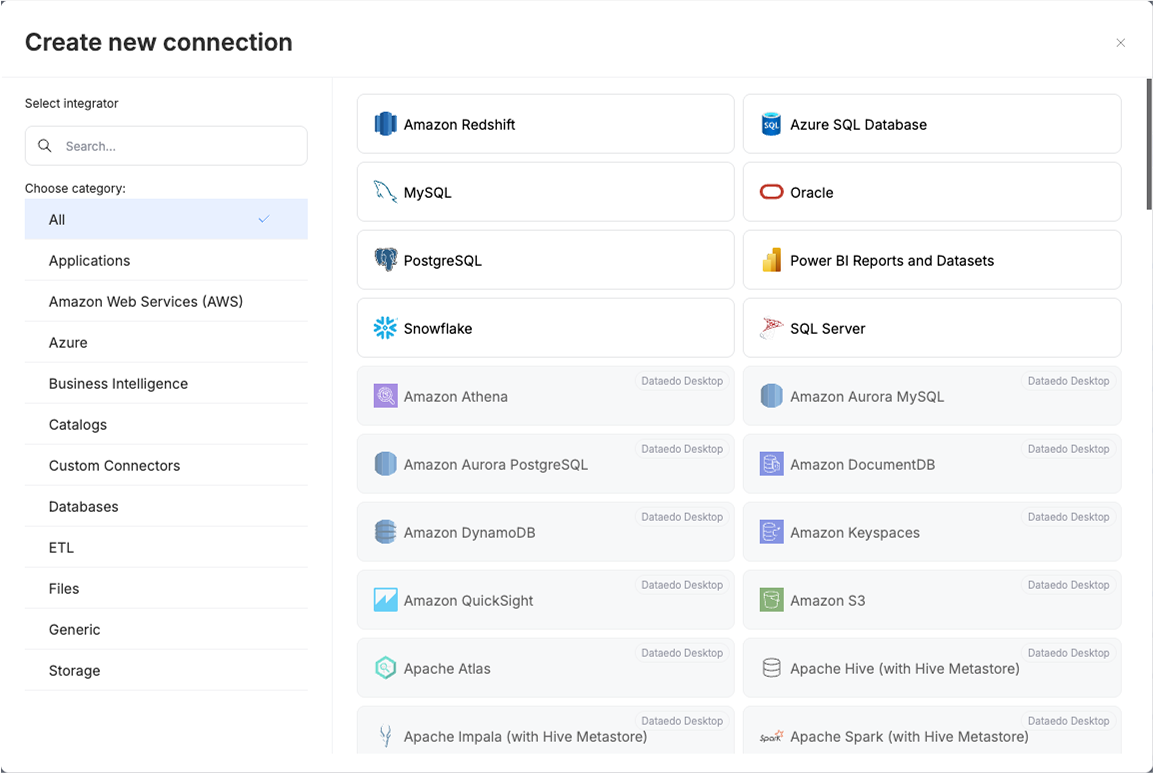
A major improvement is the ability to import multiple sources from the same host in one go. Previously, you had to repeat the entire import process for each source separately, and each one created its own Data Source. Now, you can import multiple sources at once – each will still be created as a separate Data Source, but all of them will belong to the same Connection.
Connections and shared credentials
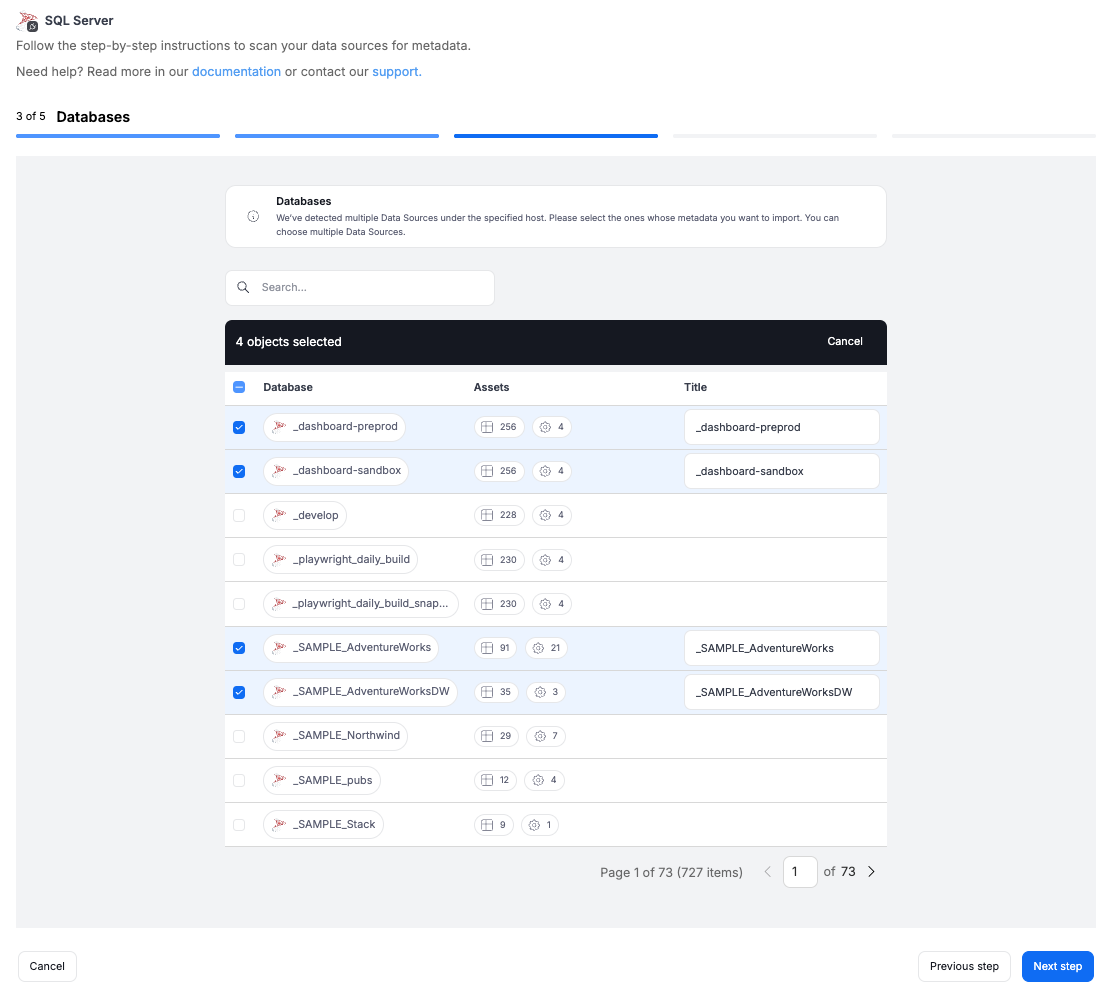
This is also the moment to highlight the Connections concept: they group shared settings such as credentials, host, and port, making it much easier to manage configurations across multiple sources. Multiple connections can reuse the same credentials, so when login details change, you only need to update them in one place. With this release, imported sources that share the same host will also share the same credentials within a single connection.
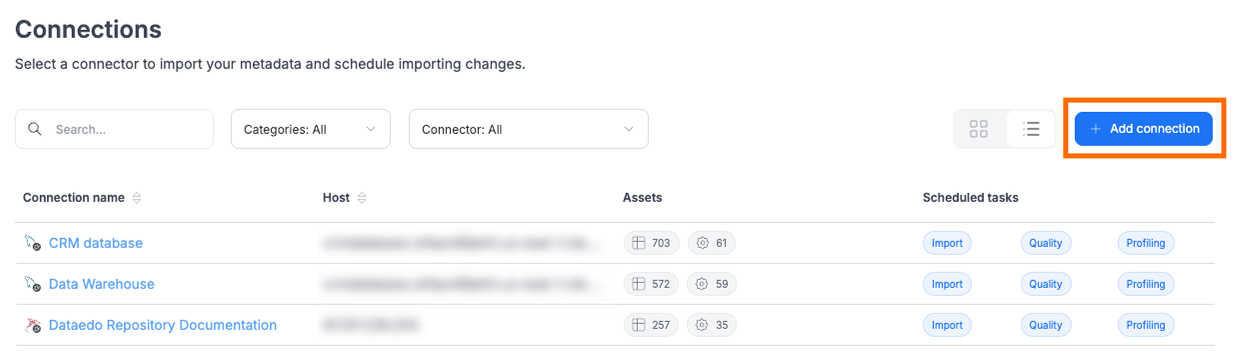
Permissions
Metadata import in the Portal can only be performed by users with the Connection Manager role. To start an import, the user needs to open Connections in the Portal and click Add connection.
Dataedo Desktop support
Importing with these connectors is still fully supported in Dataedo Desktop. We are extending functionality to the Portal, but not removing any existing options.
Data Quality
This release brings a number of new features and enhancements that make it easier to manage and monitor data quality:
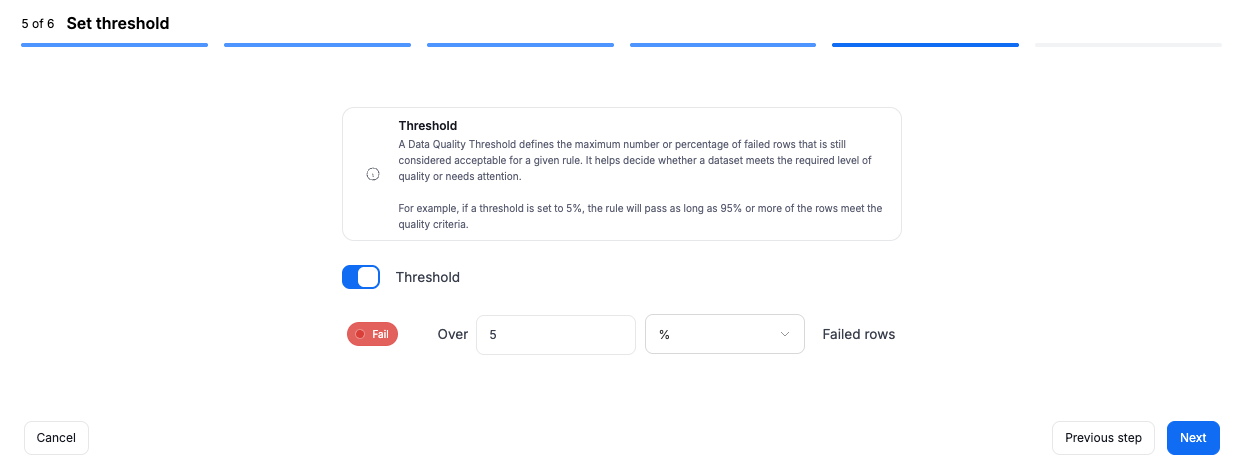
Configurable thresholds
By default, Data Quality rule instances failed if even a single row did not meet the rule’s condition. Now, you can define a custom threshold (e.g., allow up to 5% invalid rows) to make rules less strict where appropriate. Read more in the documentation
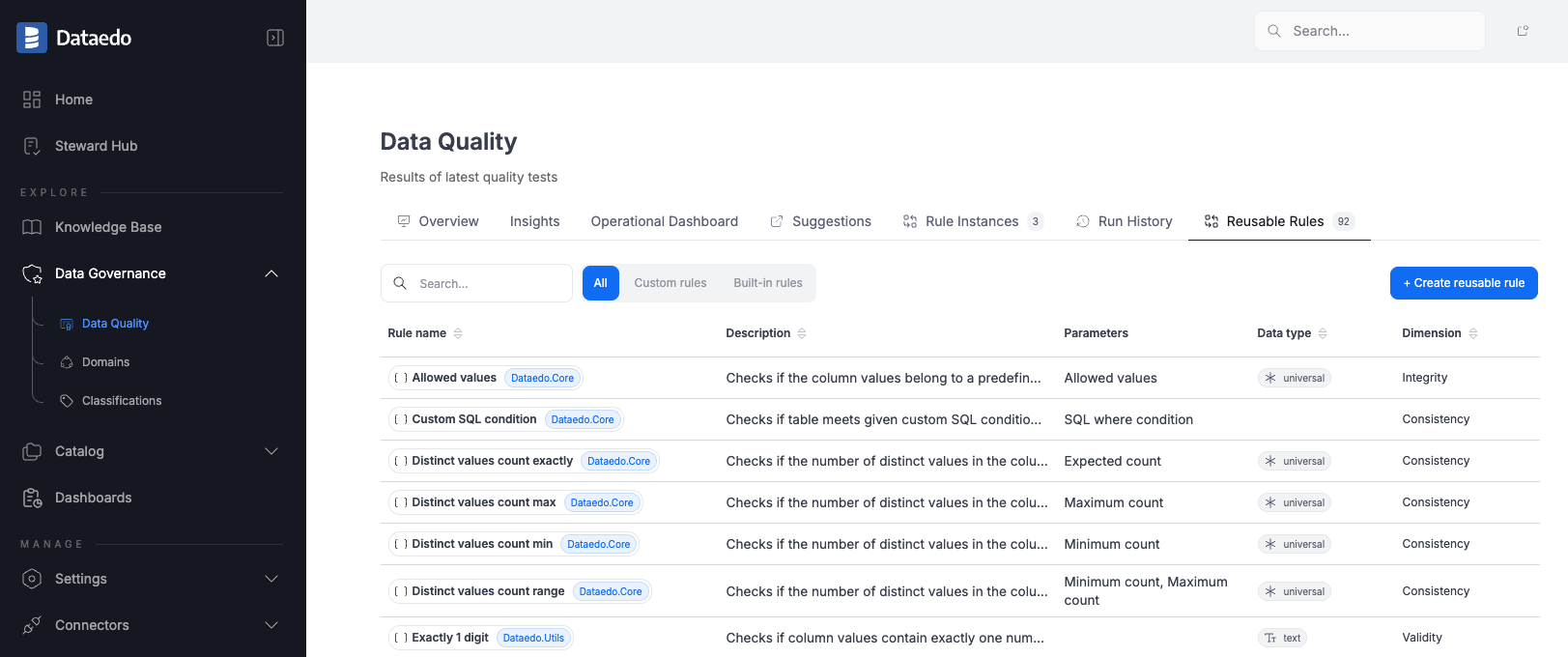
Reusable rules
In addition to single-use rule instances or custom SQL rules, you can now create reusable Data Quality rules and later assign them to any object (table, view, or column). This reduces duplication, ensures consistency, and makes it easier to manage your Data Quality setup. Only users with the Power Data Steward role at the repository level can create reusable rules, ensuring that only authorized users can define queries that access real data across connected sources. Read more in the documentation
Rules on views
Data Quality rules can now be assigned not only to tables and their columns, but also to views and their columns.
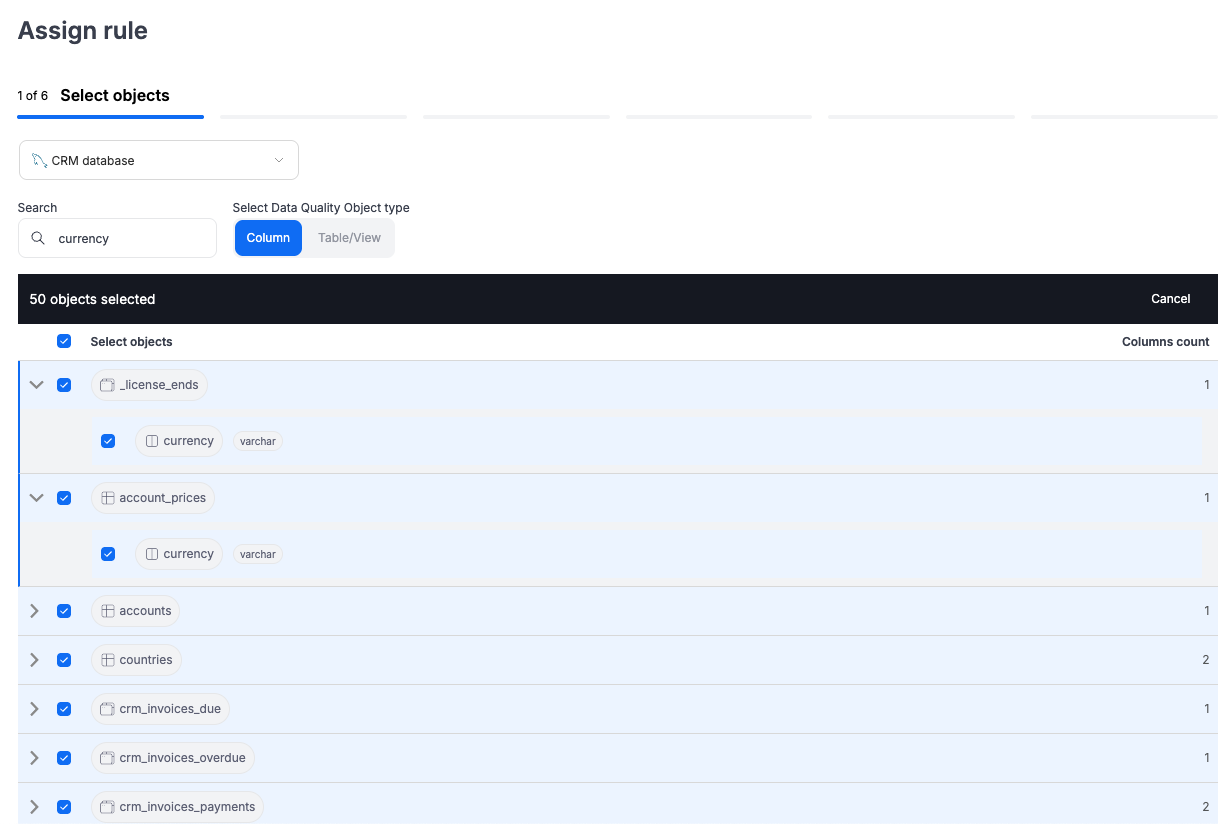
Bulk assignment of rules
Assign the same rule to up to 50 objects at once (e.g., multiple columns). This creates individual rule instances that can be managed separately later.
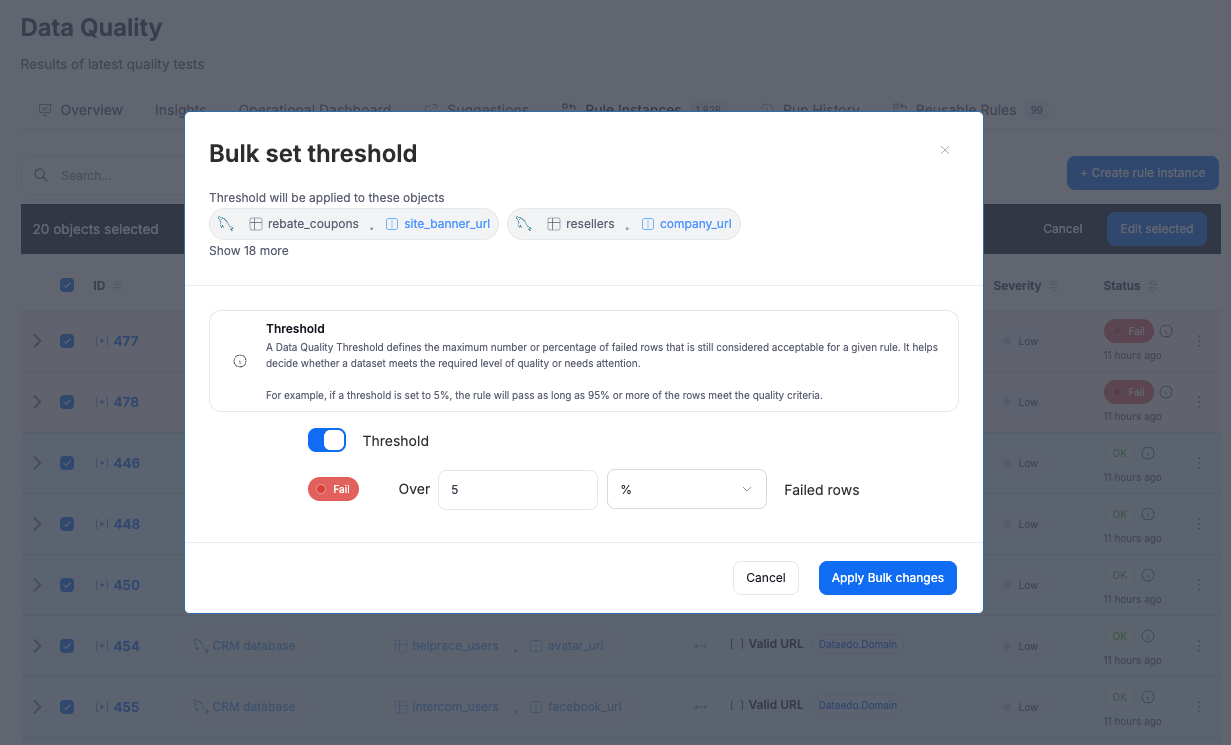
Bulk threshold editing
Thresholds can now be updated for multiple rule instances at once from any Data Quality list view. This is especially helpful for existing customers who would otherwise need to update instances one by one.
Expanded rule suggestions
We now suggest a wider set of rules based on column names and context to speed up the manual process of assigning them:
| Category | Column name contains | Suggested rules |
|---|---|---|
mail | Valid email address | |
| Government IDs | ssn, nip, pesel, ein | US SSN, Polish NIP, Polish PESEL, US EIN |
| Dates | created_at, updated_at, timestamp, expiry_date | Future dates exist, Not in future, Is fresh, No suspicious dates |
| URLs & IPs | url, website, link, ip_address | Valid HTTP address, Valid IPv4 address |
| Postal codes | zip_code | Valid US zip code |
| Identifiers & product codes | asin, iban, imei, vin, cusip, duns | Valid ASIN, Valid IBAN, Valid IMEI, Valid VIN, Valid CUSIP |
| JSON / Metadata | json, payload | Valid JSON |
Unified metrics everywhere
Both Data Quality score and Data Quality ratio are now displayed consistently across the Portal, including the Data Quality dashboard. This provides a more complete picture of data quality at every level.
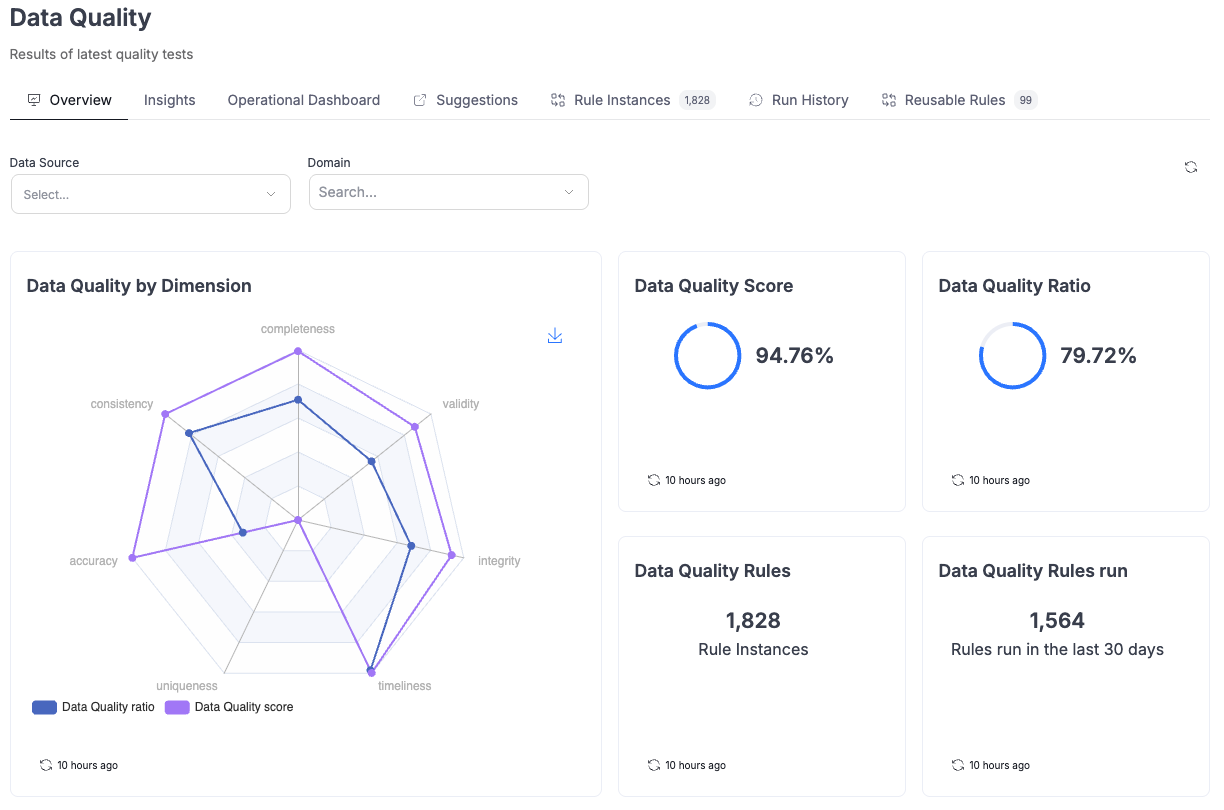
New dashboard filters
The Data Quality dashboard now supports filtering by Data Source, Business Domains, and Data Domains for more focused analysis.
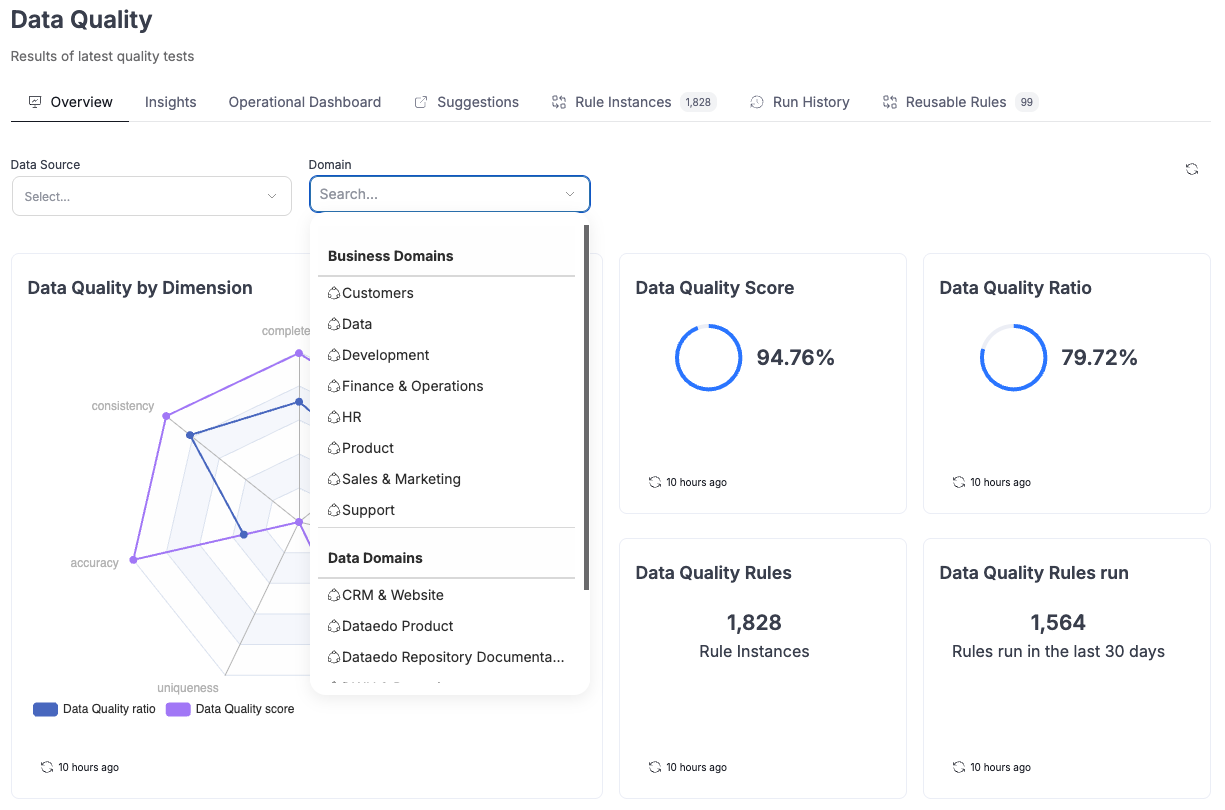
Custom failed rows count for SQL rules
When creating a custom SQL rule (for specific use cases), you can now manually provide a query that returns the number of failed rows. This is useful in situations where the default wrapping logic (SELECT COUNT(*) FROM (...)) would fail due to subquery limitations or complex SQL.
Operational Dashboard enhancements
We added an optional column Instance Description in both the Operational Dashboard and Runs History. Once enabled, it remains visible for easier tracking.
Scheduler
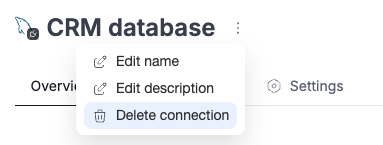
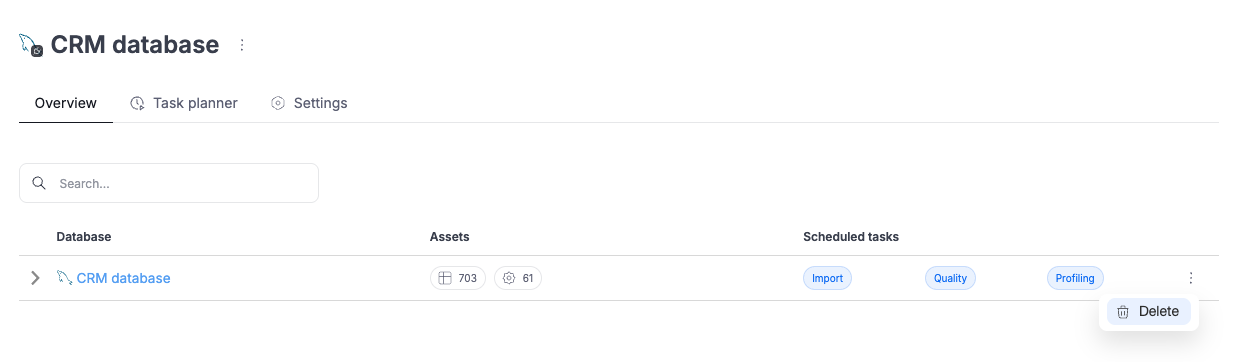
Delete data sources and connections in Portal
It is now possible to remove Data Sources and Connections directly in the Portal, without having to use Dataedo Desktop.
In progress task indicator
When a task (Metadata Import, Refresh Profiling, or Data Quality check) is currently processing, this status is now visible both in the connection header and in the Scheduler task list.
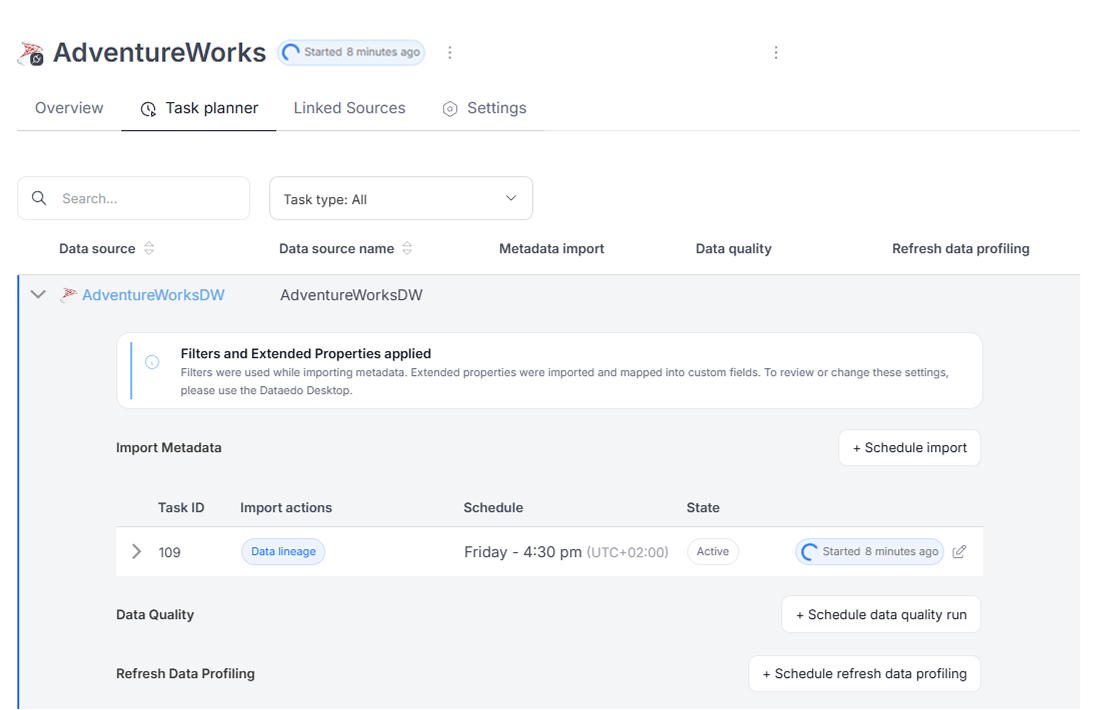
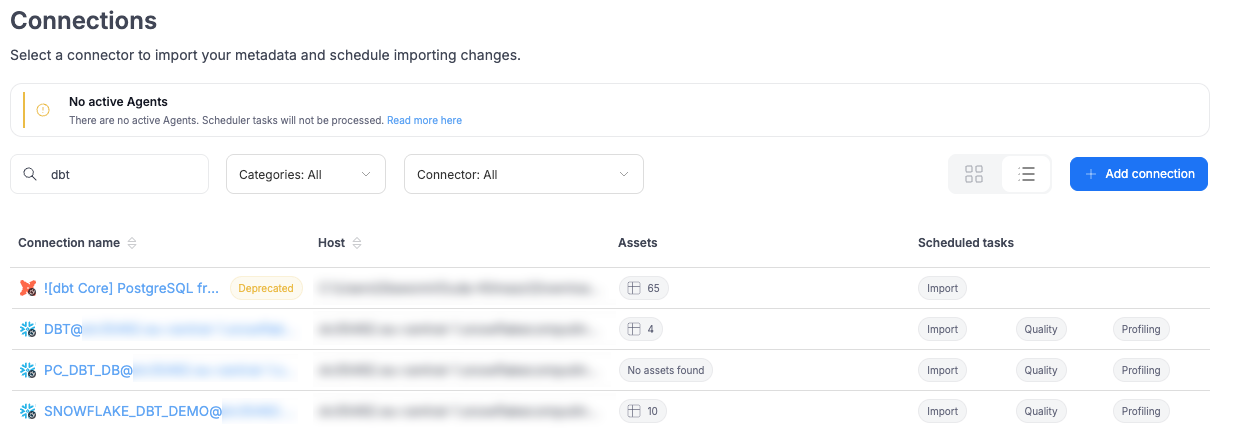
Deprecated connectors label
Connectors that are no longer supported (e.g., the old dbt integration) are now marked with a Deprecated label. Importing from these sources is no longer possible, but previously imported data remains available.
Connectors
Databricks
The Databricks connector now supports data profiling and data quality features. We have optimized the lineage extraction process – instead of calling the Databricks API for each column, lineage is now retrieved from system tables.
The connector now requires providing warehouse information during connection setup.
AWS Athena
The AWS Athena connector now supports data profiling. We also improved the handling of external tables – scripts and locations are now imported, and data lineage to source files is created automatically.
Redshift
The Redshift connector now supports data quality.
Power BI
We improved lineage when Power BI calls stored procedures to fetch data.

In addition, the import process is now noticeably faster. Datasets and dataset tables are also linked through a parent–child relationship.
SQL Server Reporting Services (SSRS)
Dataedo now supports creating lineage when a stored procedure is called to fetch data. We’ve also developed a simple app that imports report usage statistics. Please contact support if you would like to use it (requires direct connection to the ReportServer database).
SQL Server Integration Services (SSIS)
Lineage is now created when the source SQL script is stored in a variable (SQL Command from variable option). We also improved lineage when a stored procedure is called to fetch data.

SQL Server Analysis Services (SSAS) Tabular
You can now import the IsHidden property. Lineage is built correctly when column names are modified in the M Language script stage. We also improved lineage when a stored procedure is called to fetch data.
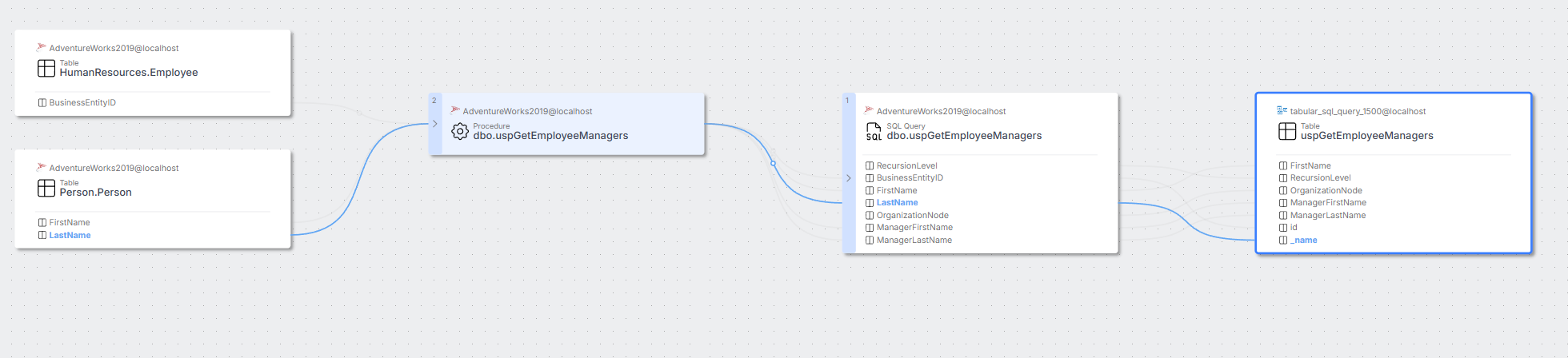
Snowflake Enterprise Lineage
We introduced behavioral changes to make imported script objects easier to document. Scripts with the same parameterized query hash are now grouped under a single object. This prevents documentation from being cluttered by cyclically executed scripts with different parameters.
If you have already used the Snowflake Enterprise Lineage connector, please note that after upgrading Dataedo, the first import changes will remove duplicate objects (with the same parameterized query hash). Only the most recently imported object will be kept.
PostgreSQL
Added import of SQL Query objects for functions with RETURNS TABLE or RETURNS SETOF. These objects:
- include the data-returning statement in the Script tab,
- have a parent–child relationship,
- have data lineage to the source tables.
MySQL
Added import of SQL Query objects for procedures that contain a SELECT statement returning data. These objects:
- include the data-returning statement in the Script tab,
- have a parent–child relationship,
- have data lineage to the source tables.
Dataedo Agent
New cross-platform application
Dataedo Agent is now a completely new, cross-platform application, no longer tied to Dataedo Desktop. It can be installed with Docker on Linux, macOS, and Windows – just like the Dataedo Portal.
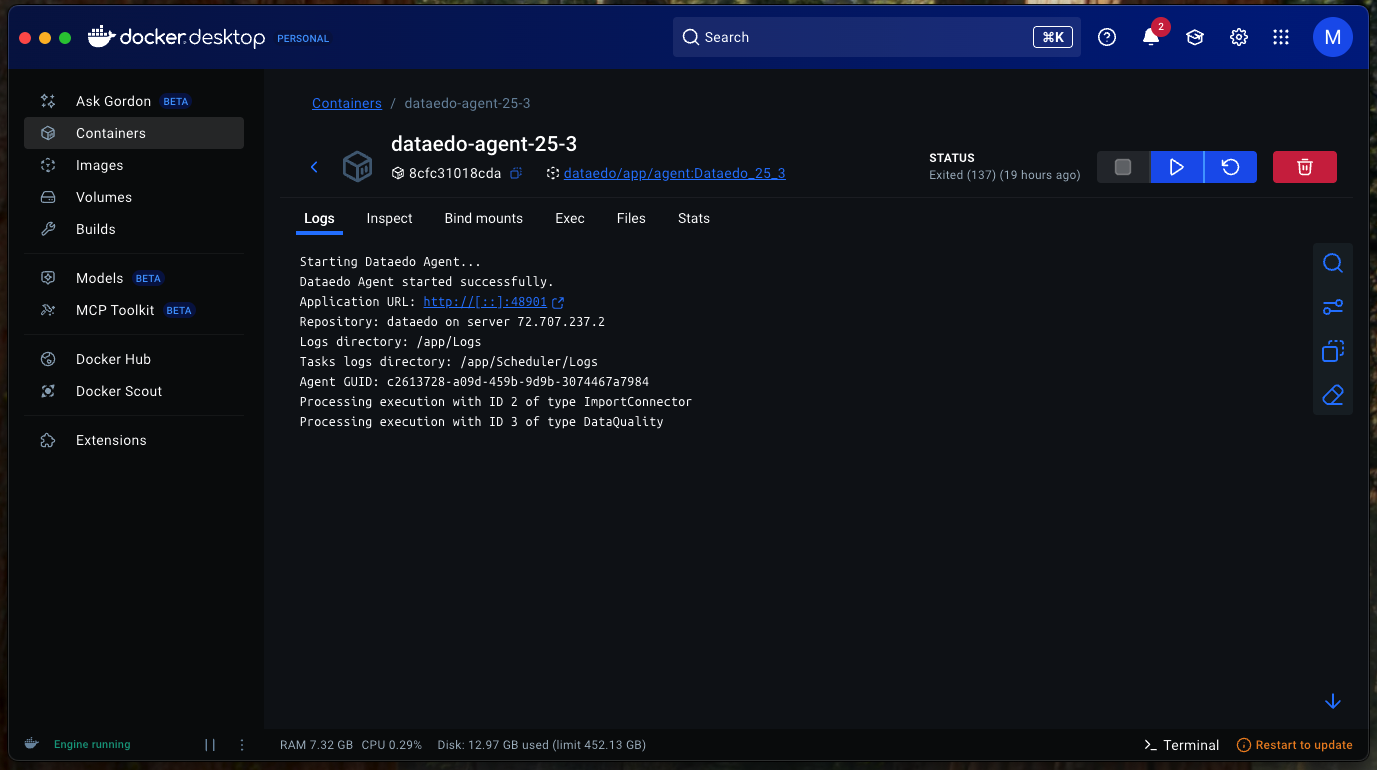
New Windows installer
For Windows users, the old console-based installer has been replaced with an improved graphical installer that makes it easier to install the Agent as a Windows Service. It also simplifies upgrading from the old Agent to the new application. Upgrading from an existing Agent installation will automatically replace it with the new application and handle all required adjustments.
Steward Hub
The Steward Hub continues to evolve into a powerful assistant for managing and improving your metadata.
Foreign key suggestions
A new section now highlights potential foreign keys for each table. Users can review these suggestions, confirm them through a verification popup, and assign a name to the new relationship before saving.
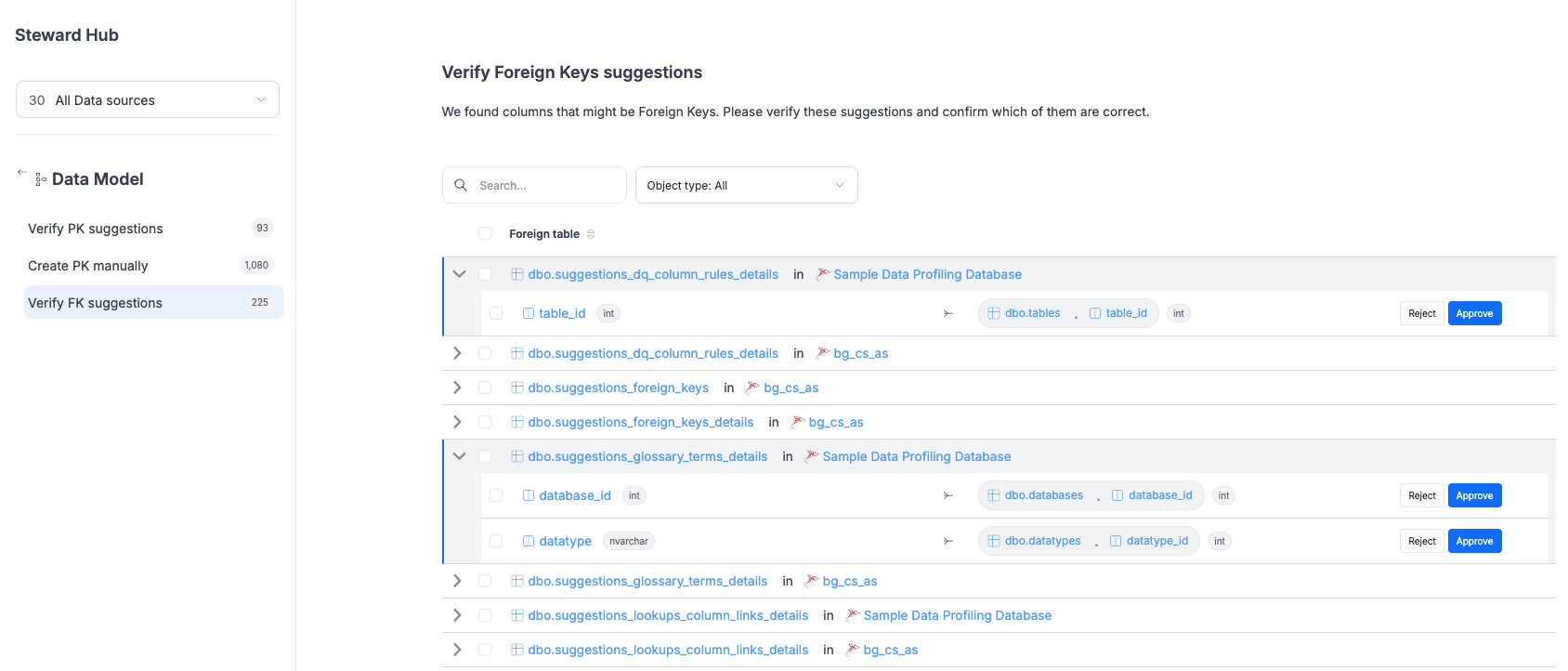
Interactive Data Quality suggestions
Suggestions in the Data Quality area are no longer read-only. Instead of re-creating them manually, you can now accept them directly in the interface for a smoother workflow.

UX/UI
This quarter we introduced a series of improvements to make the Dataedo Portal more intuitive, consistent, and pleasant to use:
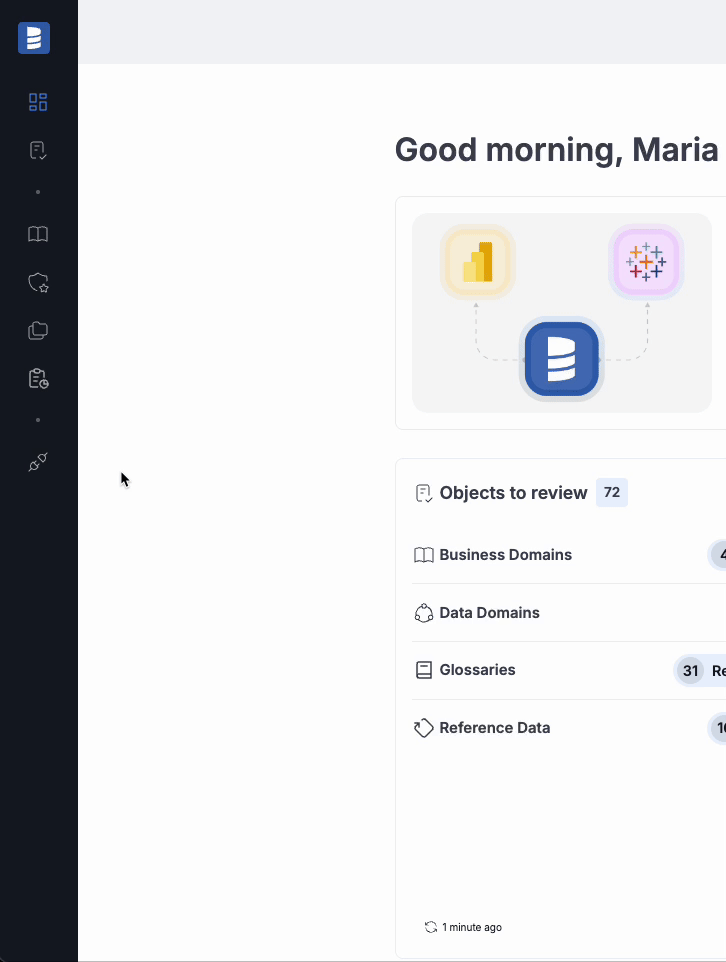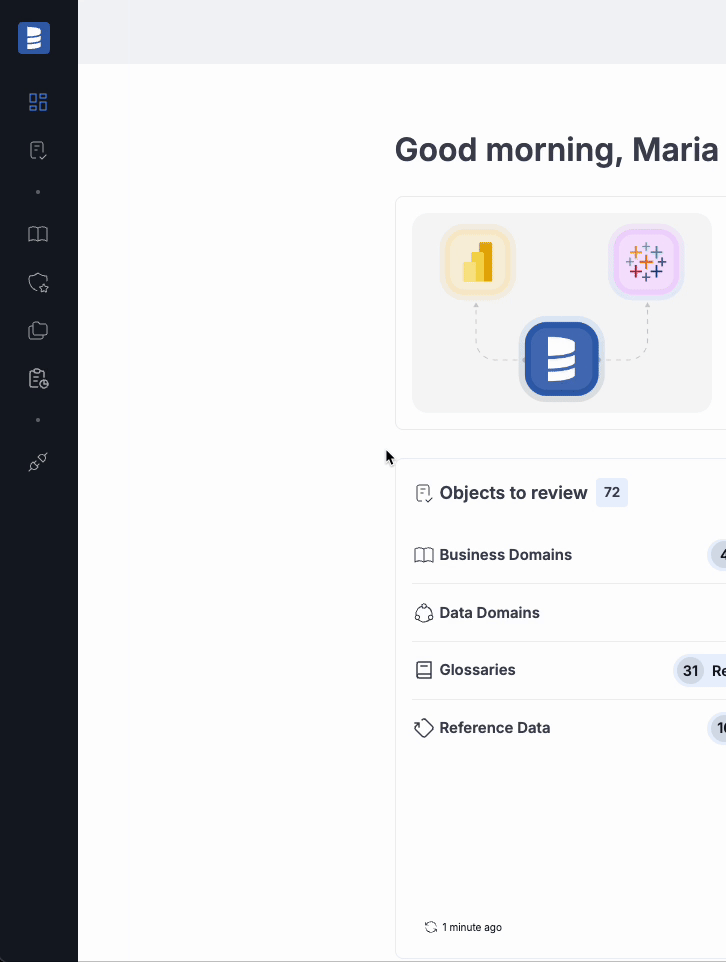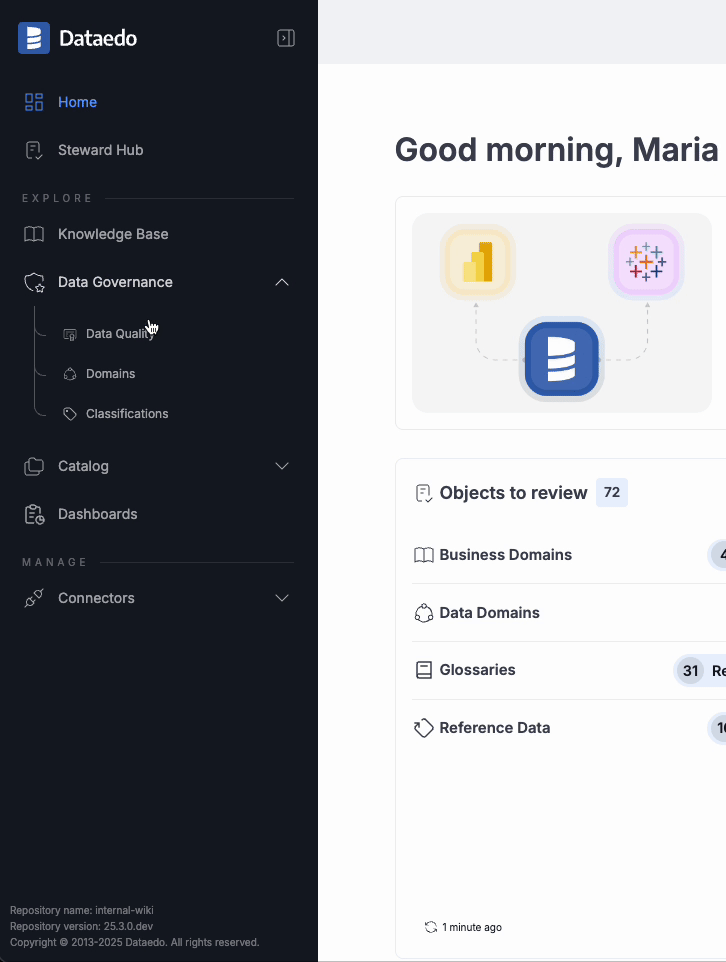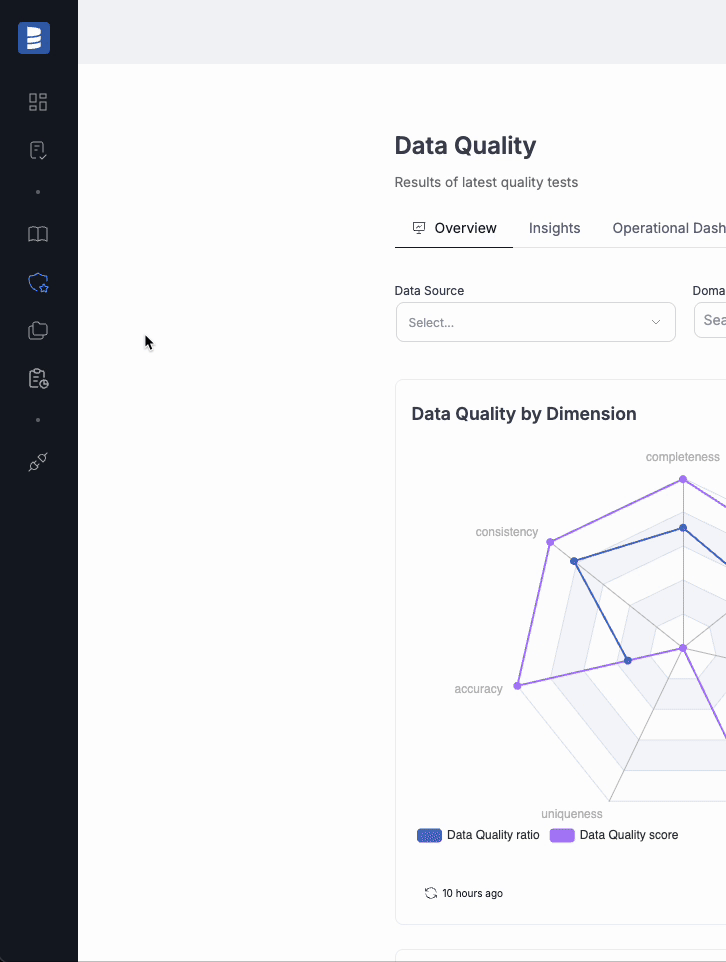
Smarter navigation
The sidebar now expands on hover to show all section names and collapses automatically when you move away. Even in the collapsed view, your current section stays highlighted, saving space without losing orientation.
Consistent layouts
All pages now follow a unified layout. For example, domains adopt the same look and feel as data products, including counters of linked objects for a clear overview.
Refreshed components
Tags, badges, and checkboxes received a redesign for a cleaner and more consistent look across the app.
Filters in URLs
When copying a link, applied filters, sorting, and pagination are now included in the URL, making it easier to share exact views with others.
Login
We’ve refined authentication to make login more reliable and better aligned with user management:
Email field synchronization for SAML
When logging in with SAML, the email value from the SAML response is now stored not only in the login field but also in the email field in Dataedo. For existing users, the system automatically fills in the missing email field during login if it was previously empty.
Default login method fix
We corrected an issue from the previous release. It is now possible to select only one default login method. In the case of SAML, this means that only a single provider can be set as default, instead of the entire login method.
Other improvements
We also introduced several technical enhancements and options requested by our users:
Task scheduling via Public API
In version 25.2 we removed the ability to schedule tasks (Metadata Import, Refresh Profiling, Data Quality) via command line. This functionality is now restored in a new and more flexible way: through the Public API.
GET /public/v1/scheduler/tasks– returns all scheduled tasks with their IDs.POST /public/v1/scheduler/tasks/{taskId}/trigger– triggers a specific task by ID.
Tasks triggered this way also appear in Schedule → Calendar in the Portal. In the details, they are marked with:This task was triggered manually via Public API.
New repository creation option
Until now, in Portal creating a new repository meant either letting Dataedo generate a fresh one, or connecting to an existing repository. We have now added a third option: you can prepare your own empty database, and Dataedo will create all the necessary tables and structures inside it. This gives you full flexibility to choose the exact database type, pricing tier, and configuration you prefer.