Connecting to dbt Cloud
Supported versions
Dataedo’s dbt connector works with both dbt Core and dbt Cloud starting from version v1.0. The connector is platform-agnostic, so you can use it with any warehouse supported by dbt - Snowflake, BigQuery, Redshift, and more. For the lineage support, make sure that the warehouse is connected to Dataedo as well.
Prepare for import
Dataedo needs two dbt artifacts to import metadata:
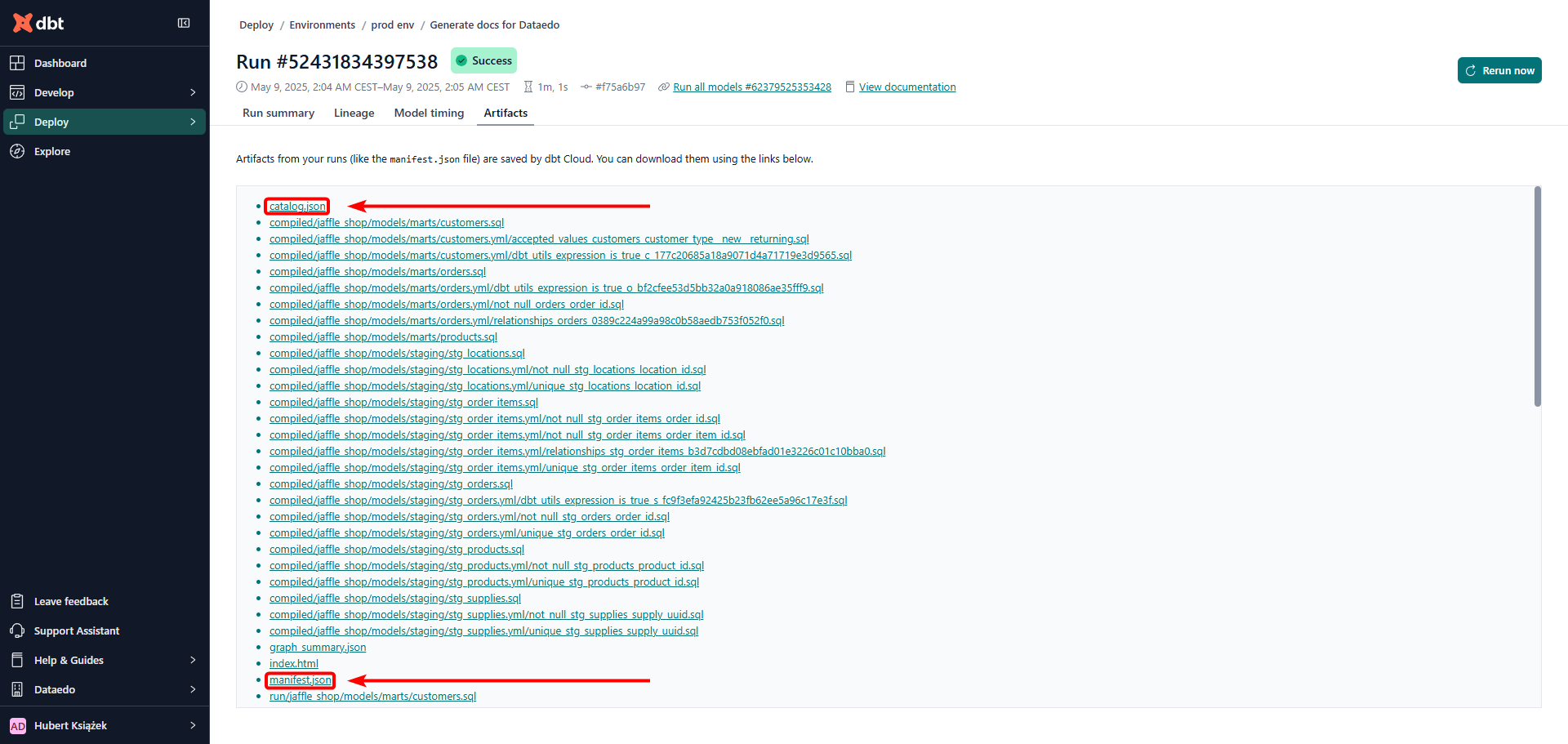
manifest.json- produced by any dbt command exceptdbt deps,dbt clean,dbt debug, anddbt init,catalog.json- produced bydbt docs generatecommand.
See below for details on how to generate or retrieve these files.
Generate the dbt docs artifacts
To let Dataedo import metadata from dbt Cloud, make sure your job has Generate docs on run enabled. For details, see the dbt Cloud docs.
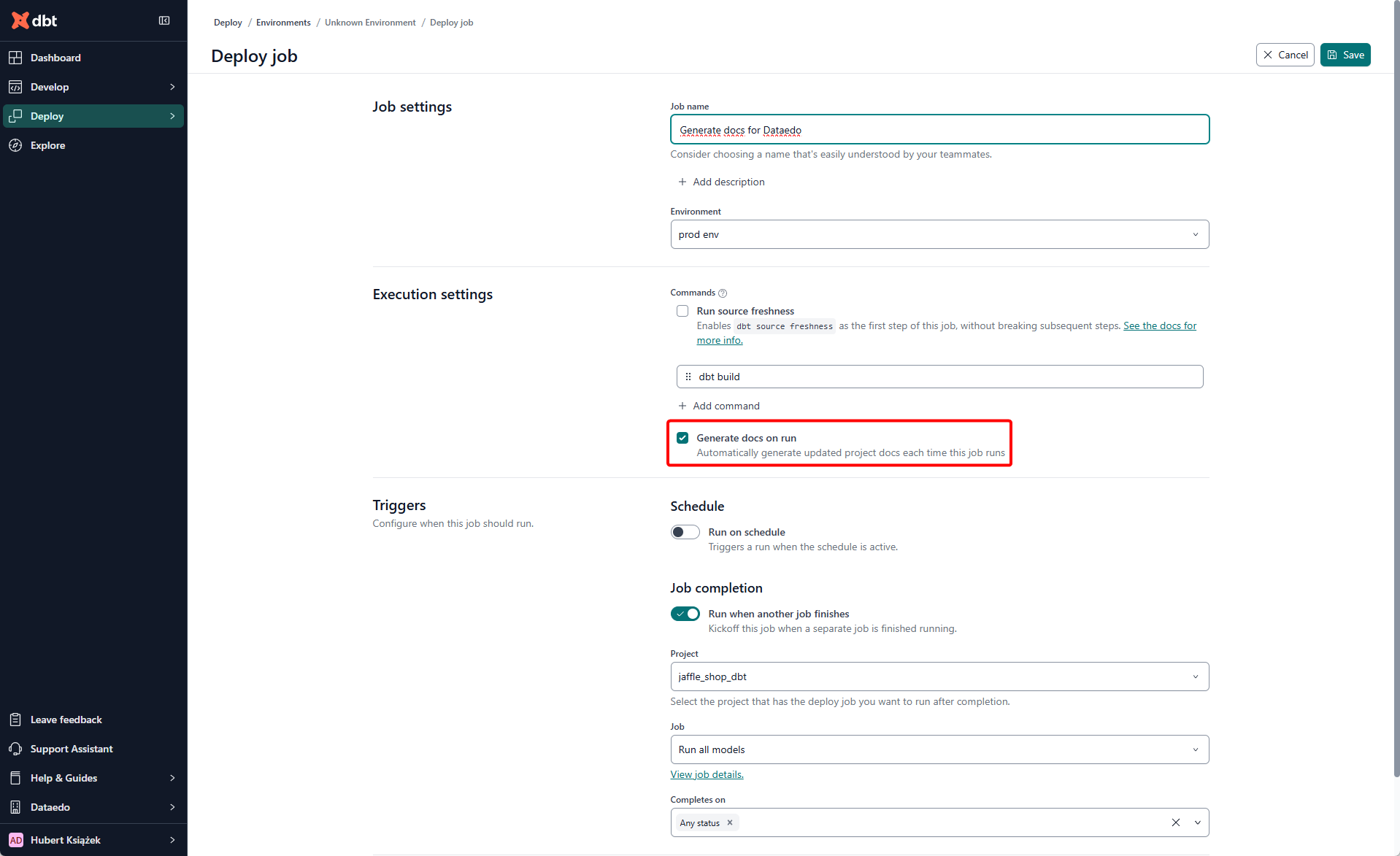
Adding a manual dbt docs generate command will not help—Dataedo ignores that step. What matters is that the Generate docs on run checkbox is ticked in the job settings.
Ideally, enable Generate docs on run in your main production job (the one that materializes your models). If you prefer a separate docs-only job, schedule it immediately after the main run so the models already exist; otherwise the generated docs—and thus the import may be incomplete.
Locate the Administrative API endpoint
Dataedo needs the administrative API endpoint of your dbt Cloud instance. You can copy it from the Settings page or straight from the browser’s address bar:
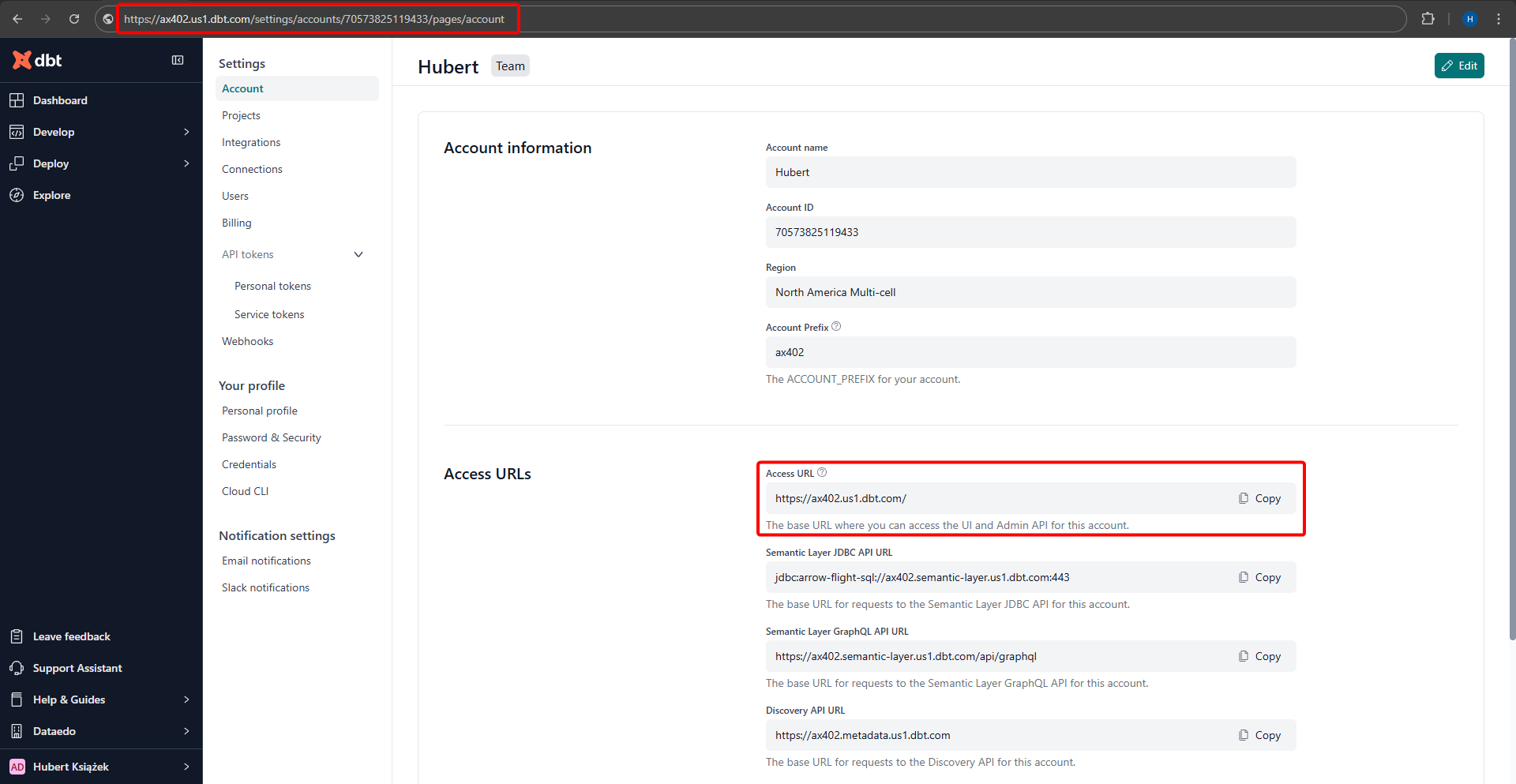
See the dbt Cloud Admin API docs for reference.
Create an authentication token
You can authenticate with either of the following:
- Personal Access Token - see persona-token guide.
- Service Account Token - see service-token guide; must cover the endpoints listed below.
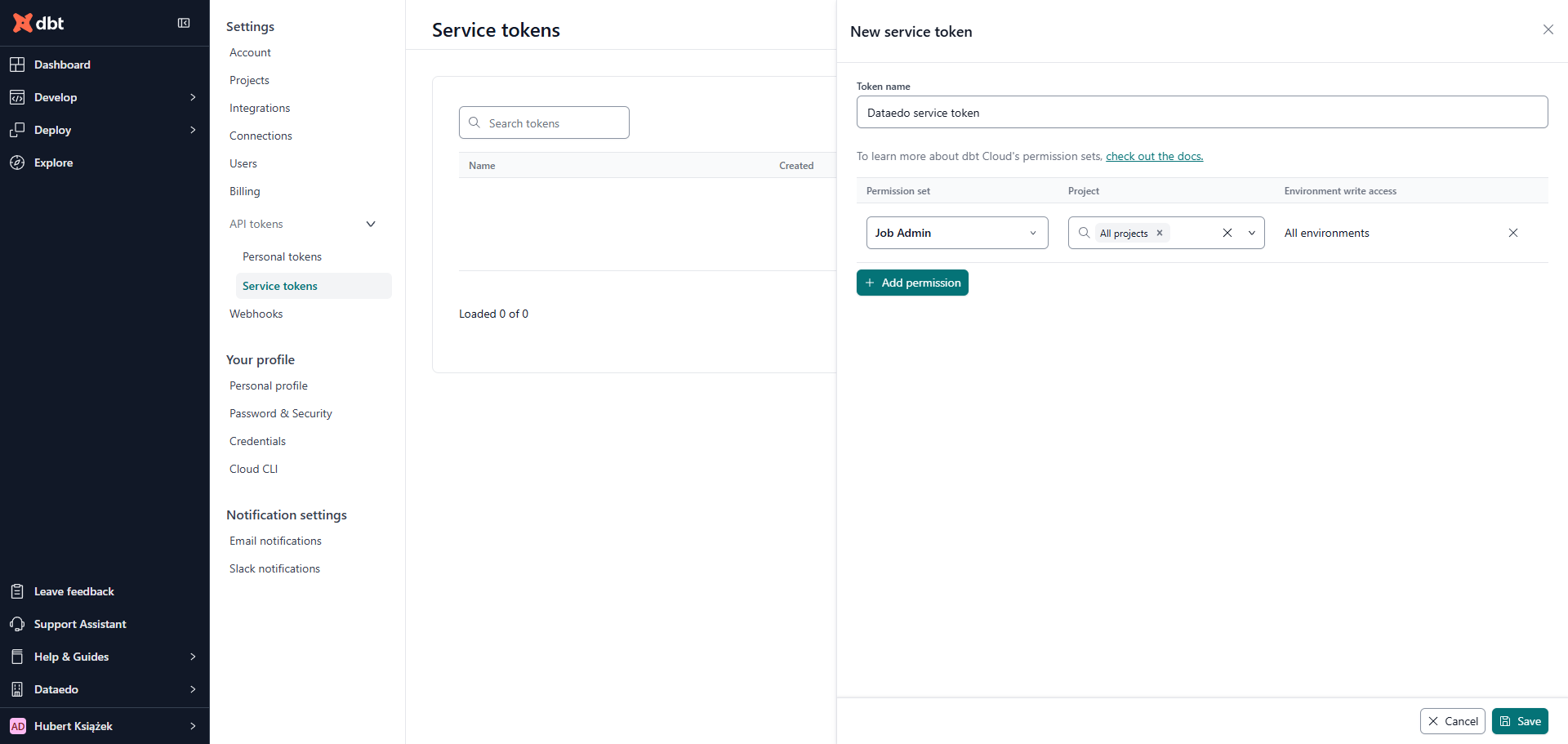
Required permissions
Dataedo calls these administrative API endpoints to retrieve metadata:
- GET
/api/v3/accounts/ - GET
/api/v2/accounts/{account_id}/jobs/ - GET
/api/v2/accounts/{account_id}/jobs/{job_id}/artifacts/manifest.json - GET
/api/v2/accounts/{account_id}/jobs/{job_id}/artifacts/catalog.json
Access to these endpoints typically requires the Job Admin permission set. For enterprise environments, the Job Viewer permission set may also provide sufficient access, although this configuration has not been formally verified.
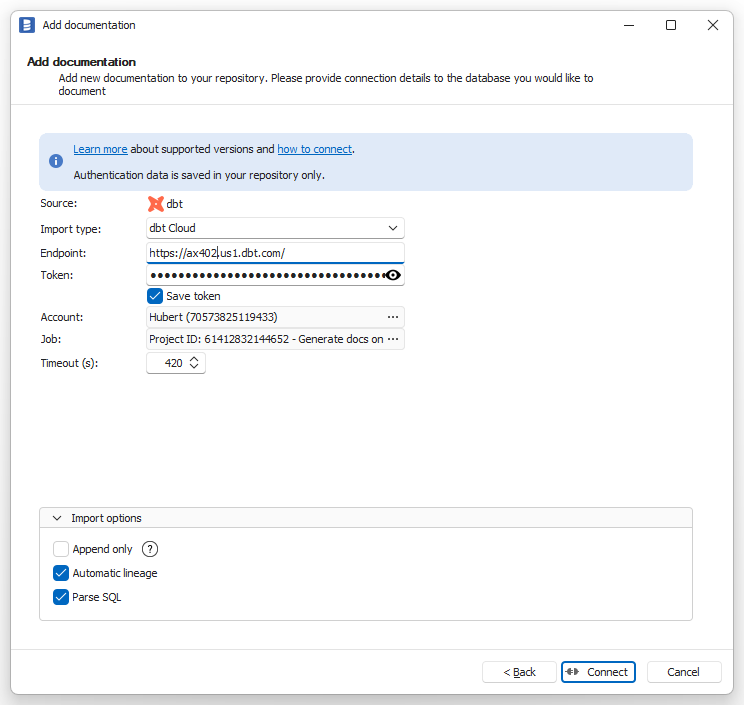
Filling in the connection form
Choose dbt Cloud as Import type and fill in the following fields:
- Endpoint - the URL of your dbt Cloud instance (e.g.,
https://cloud.getdbt.com/,https://{account_prefix}.us1.dbt.com/,https://emea.dbt.com/) - see section above for more information. - Token - your Personal Access Token or Service Account Token - see section above for more information.
- Account - name of the dbt Cloud account with access to the project and job you want to import metadata from.
- Job - name of the job with 'Generate docs on run' option enabled - see section above for more information. To make the choice easier, the job name is prefixed with information about the project it belongs to.
After the first import - activate automatic lineage
The initial import brings in objects and descriptions, but lineage is empty until you set up the Linked sources and run Import changes. Follow the steps below to create automatic lineage.
What is a linked source?
A linked source identifies which documentation set inside Dataedo represents a particular external system. By mapping it, you remove the ambiguity that appears when identical object names exist in several documentations—Dataedo now knows exactly where to look to resolve cross-database lineage.
Need more context? See the Linked sources overview.
In dbt, Dataedo creates three kinds of linked sources:
| Linked source type | When it is created | Name in Dataedo |
|---|---|---|
| Project | Always. Represents the whole dbt project. | Always Project warehouse |
| Seed | Only if the project contains seeds. | Always Seeds |
| Source | One per source defined in your dbt project. | Same as the source name in dbt. |
Map each linked source to the right database
| Linked-source type | Map it to documentation that represents… |
|---|---|
| Project | The database where dbt models (and seeds) are materialized. |
| Seed | The database that holds the seed .csv files, not the database where the seeds are materialized. |
| Source | The upstream database referenced by that specific source in dbt. |
For step-by-step instructions on assigning a linked source to a documentation set, see the overview.
A linked source can point to several documentations - for instance, if you imported the same database multiple times, but one schema at a time. In most scenarios, though, you will connect each linked source to a single documentation.
Run Import changes
After you assign the linked sources, run Import changes to populate the lineage. Dataedo will now automatically create the lineage.
Remember to update the linked sources whenever you add/update the sources in your dbt project. The automatic data lineage feature only works if the linked sources are up to date.
Import dbt Cloud without internet access
If your Dataedo instance does not have internet access, you can still import dbt Cloud metadata. To do this, you need to download the artifacts manually and then import them into Dataedo using dbt Core (artifacts from path) connection type.