Oracle - Data Quality
Oracle Database—Data Quality
With Data Quality, you can define quality checks, choose from 80+ predefined rules, monitor failed rows over time, and schedule automated checks. This feature allows your teams to maintain high data quality and quickly address quality issues once they arise.
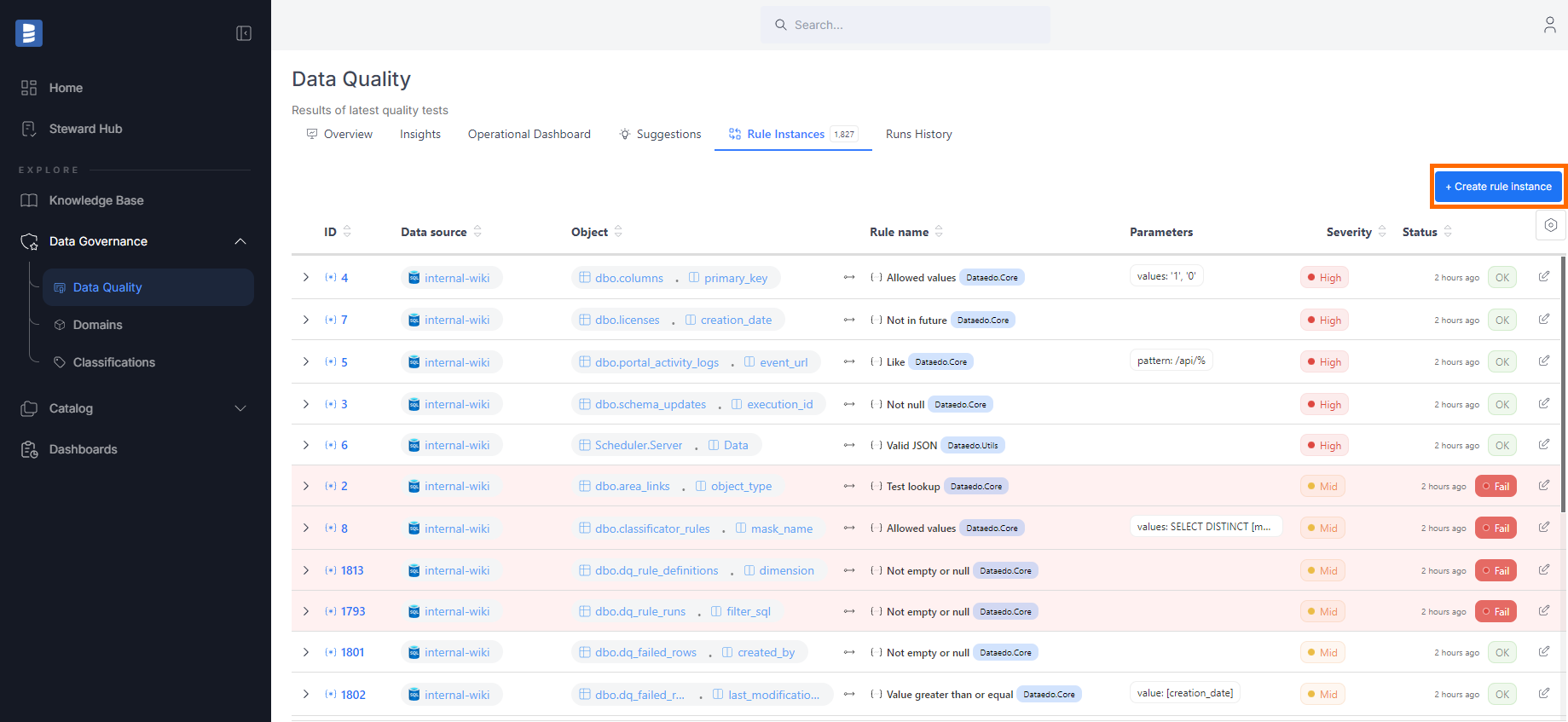
Create rule instances
Data Quality rules define the criteria for acceptable data, while instances represent the application of those rules to columns. You can create rule instances in three ways:
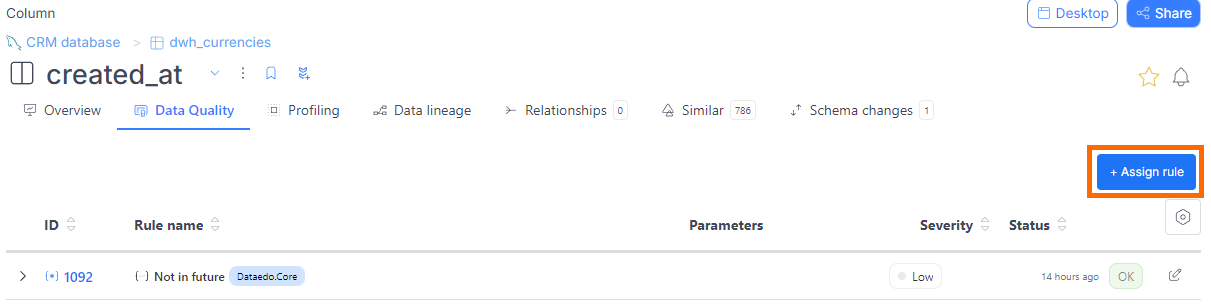
- From a column
- From a table
- From the Data Quality tab
- Find the table you're interested in.
- Navigate to its Data Quality tab.
- Click the Create rule instance button.
- Select a column from the table, then choose the rule you want to apply.
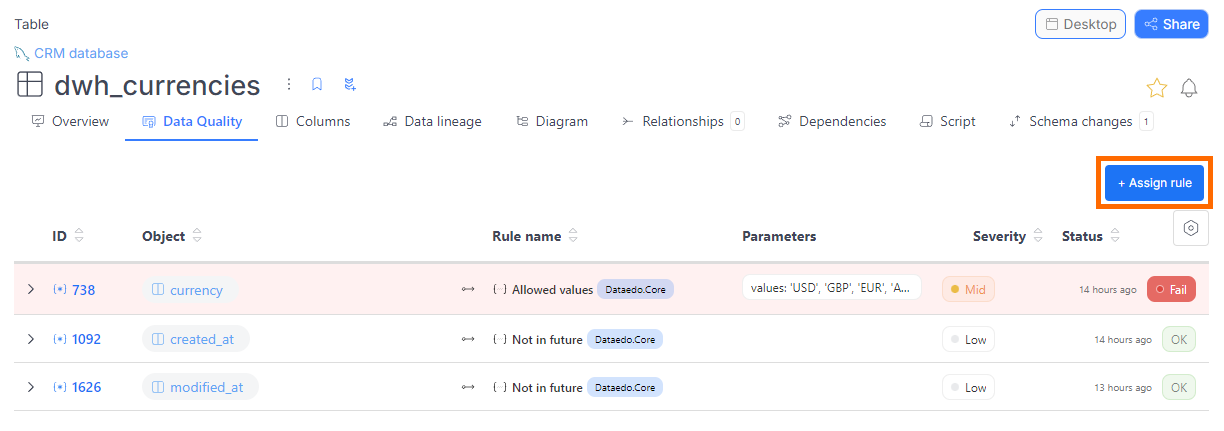
- Navigate to the Data Quality tab in the main menu.
- Go to the Rule Instances tab.
- Click the Create rule instance button.
- A popup will guide you through selecting a data source, table, and column, followed by choosing a rule.
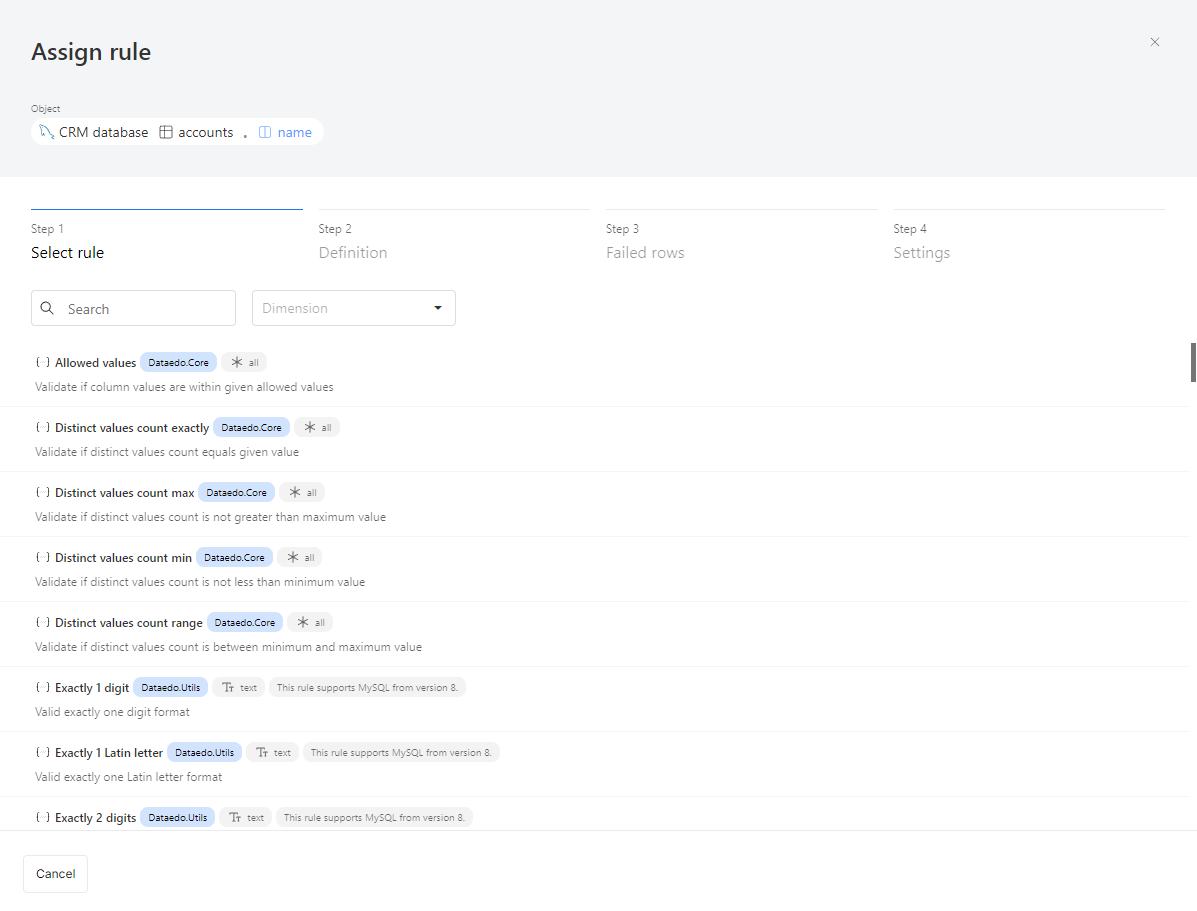
After selecting a column, the first step is to choose a rule. Each rule has the following attributes:
- Name and description: Explains what the rule checks.
- Library: The rule belongs to a specific library. In the future, you'll be able to create your custom rule library.
- Applicable column types:
- All: Can be assigned to any column type.
- Text: For string-type columns only.
- Date: For date-type columns only.
Assigning a rule
- Step 1: Select a Rule
- Step 2: Parameters & Filters
- Step 3: Failed Rows
- Step 4: Settings
Choose a rule for the selected column. Each rule has:
- Name & description – Explains what it checks.
- Library – Where the rule belongs.
- Applicable column types – Defines where it can be used (All, Text, Date).
Warnings (such as compatibility issues) will be displayed here.
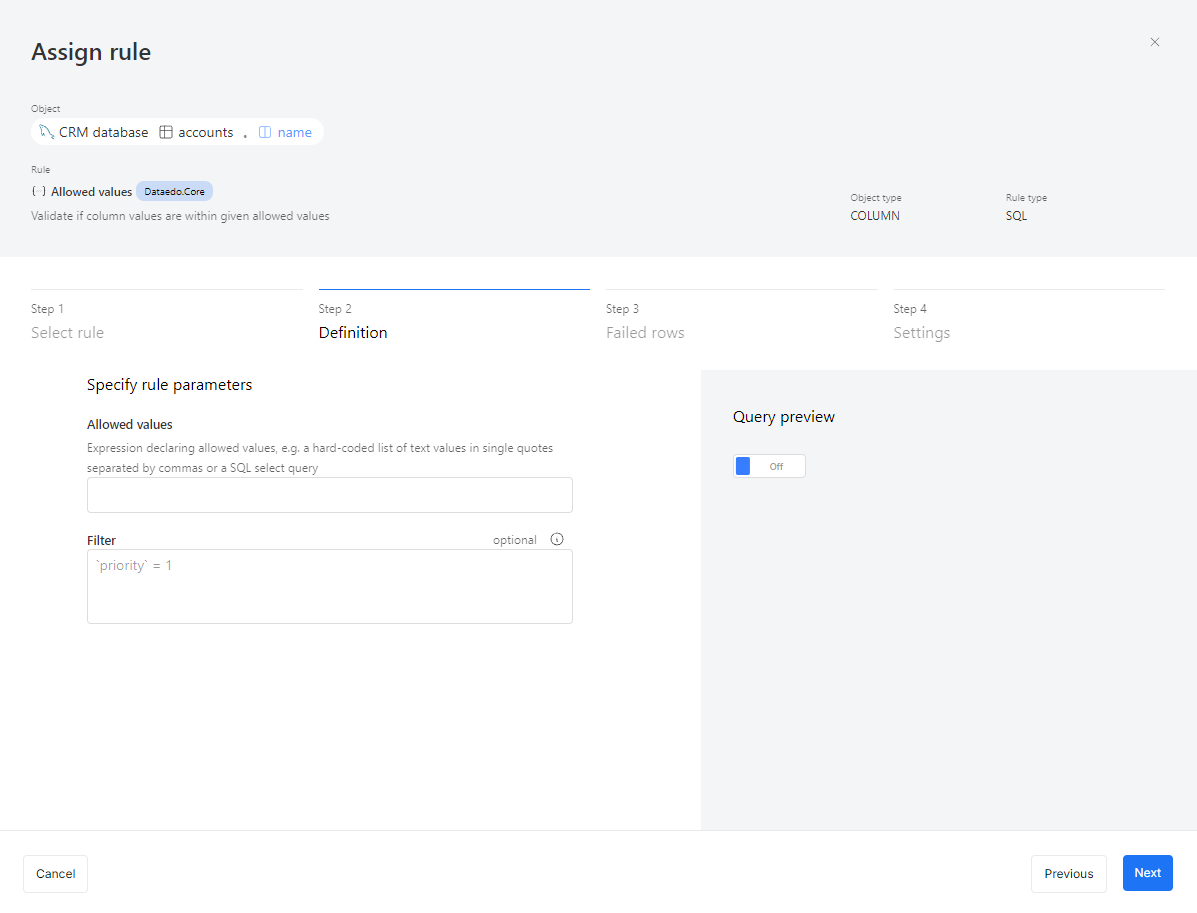
Some rules require additional inputs:
- Not null – No parameters needed.
- Allowed values – Define valid values.
- Value range – Set min/max limits.
Optionally, apply filters to check only specific records (e.g., invoices marked as high priority).
- Filter syntax depends on your connector (e.g.,
[priority] = 1for SQL Server).
You can also preview queries:
- Raw rule query – With placeholders.
- Instance rule query – With applied parameters.
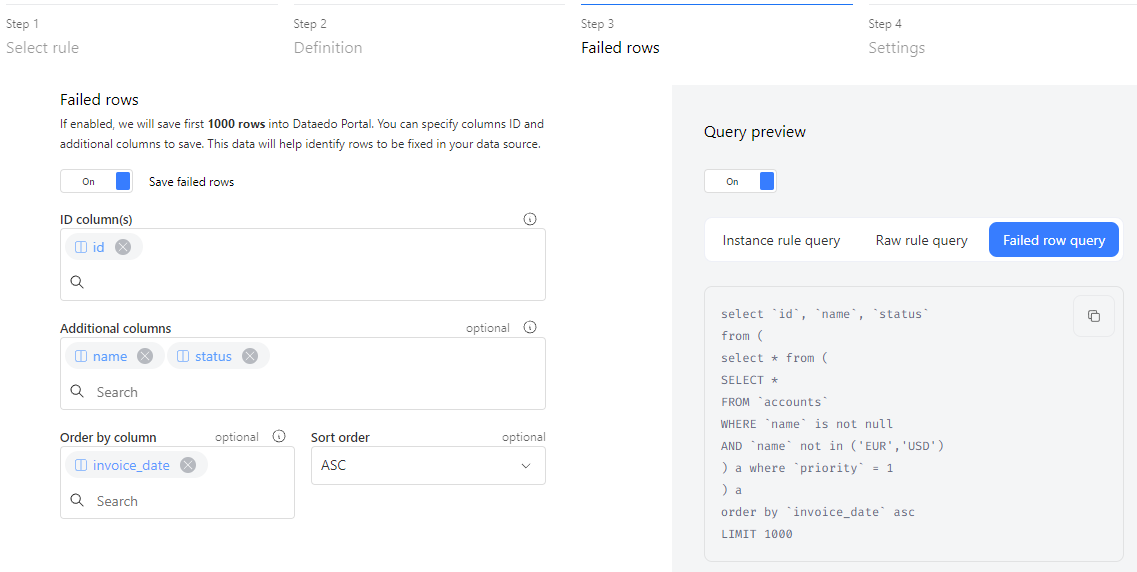
By default, Dataedo collects numeric statistics. Enable failed row collection (up to 1,000 rows) to review issues. You'll need:
- ID column(s) – To uniquely identify failed rows (defaults to Primary Key).
- Additional columns – For extra details.
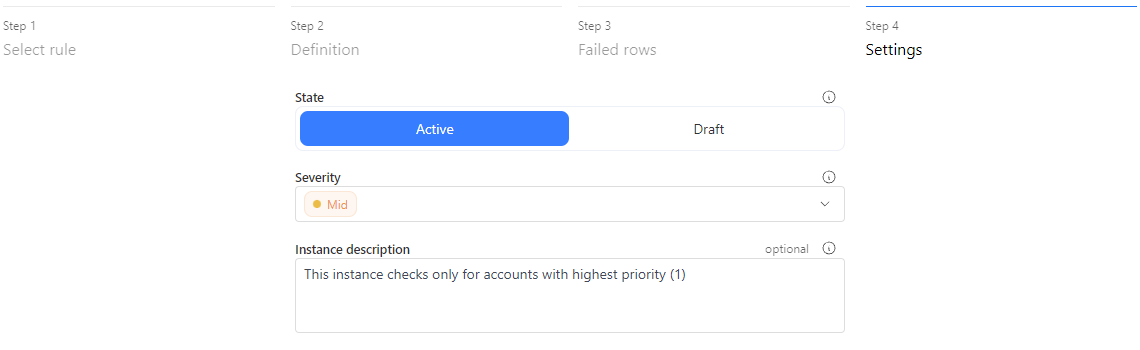
- Active – Runs during scheduled checks.
- Draft – Inactive until manually enabled.
- Severity – Defines rule priority (e.g., critical rules run daily).
- Description – Useful for noting applied filters or rule scope.
Browse results
Dataedo lets you track data quality across columns and tables. You can see data quality scores, check rule instances with severity and status details, and review historical trends. The Data Quality tab lists all rule instances, showing tested rows, failures, and execution timestamps.
Data Quality dashboards show key metrics, rule counts, and status breakdowns, helping you spot issues and track trends. Whether checking individual rule instances or assessing overall data health, these tools give you a clear view of data quality.
Check the Data Quality documentation to learn more.
Run data quality
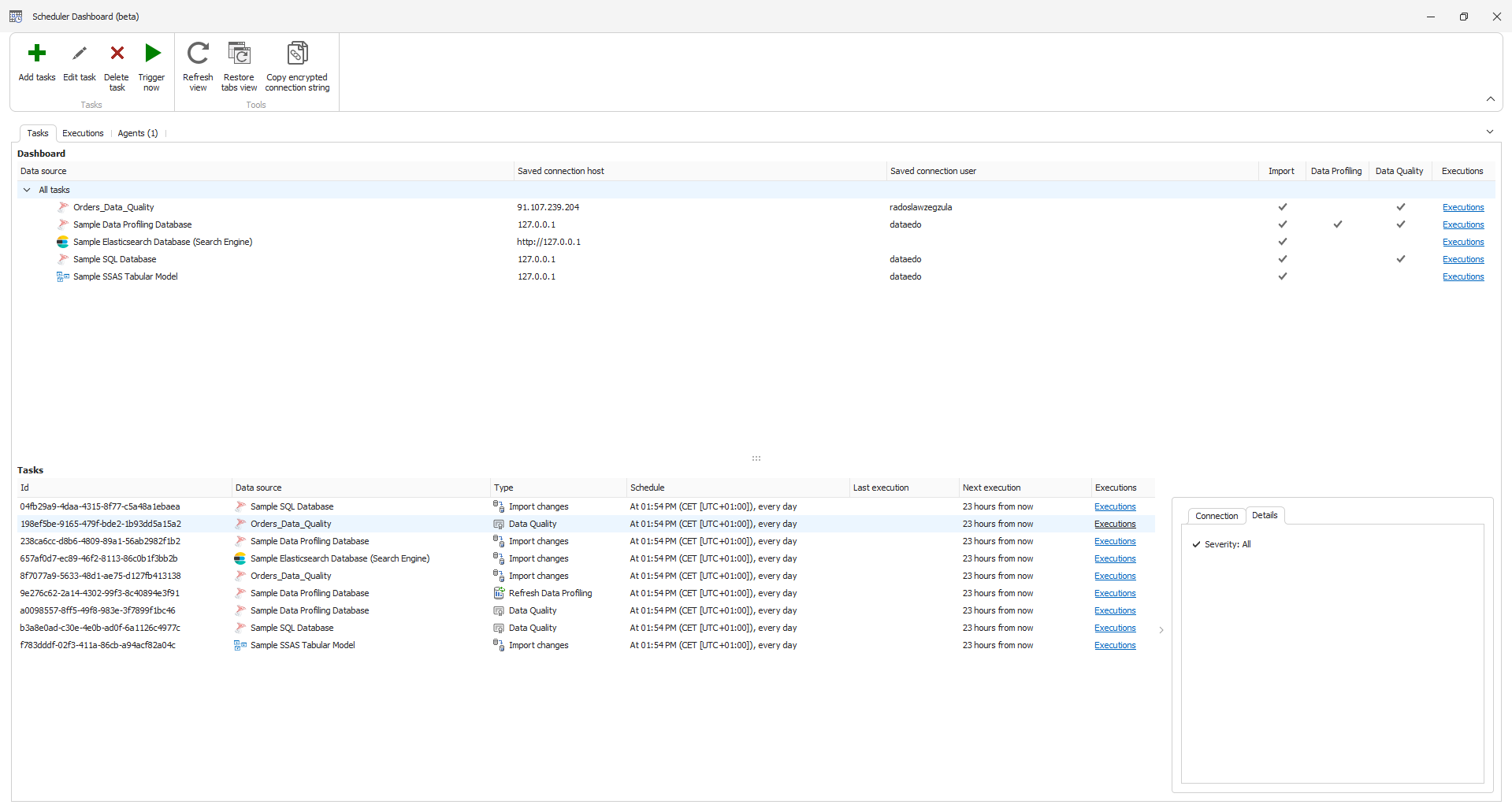
Data Quality runs through Dataedo scheduler, and you can find detailed setup instructions in this document.
It is a standalone task you can select, similar to scheduling imports or profiling. The key difference is that you can schedule runs based on the severity of the instances. This allows you to prioritize higher-severity instances, running Data Quality checks more frequently for critical issues, while lower-severity instances can be scheduled separately to run less often.
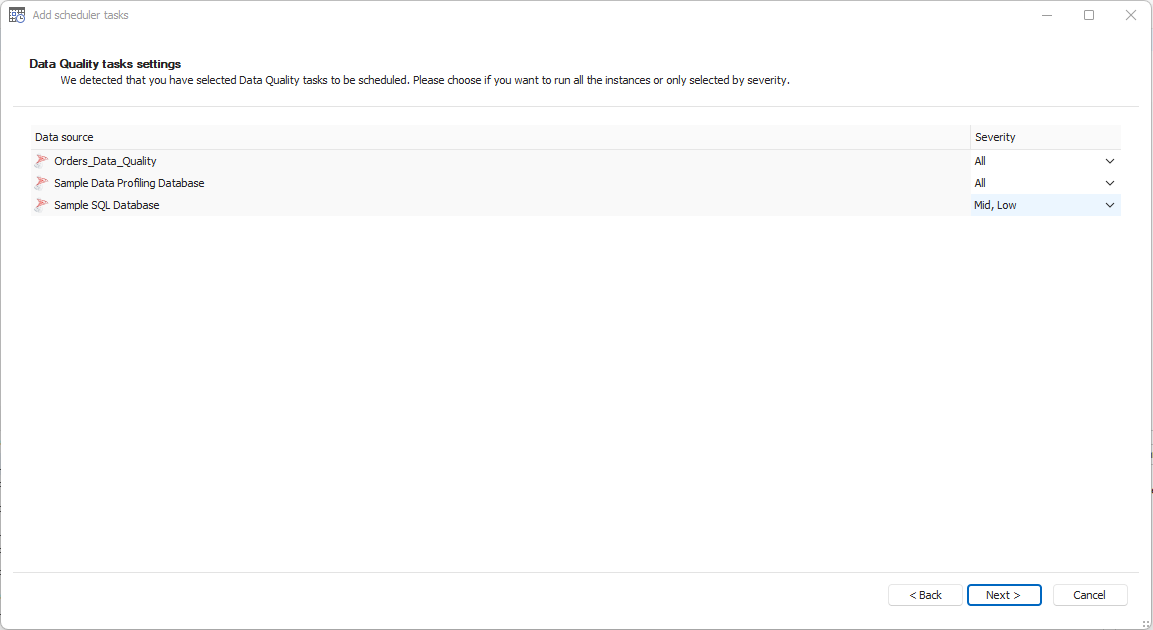
The rest of the scheduling process is the same. You can test your connection, specify how often the task should run, and adjust the Data Quality tasks to include instances based on their severity.