Overview—Data Profiling
The Data Profiling module helps explore and understand the data stored within databases such as Overview. It combines essential metrics with an intuitive user interface, which allows you to delve into the most common or random data from tables or views.
What is Data Profiling?
Data Profiling involves examining data to gather statistics and metrics that provide insights into data structure and potential issues. You can use it for:
Overview of Data Profiling
Table row count
The profiling tool scans each table to count the number of rows, providing an up-to-date row count displayed in the Dataedo Desktop and the Dataedo Portal. This count is refreshed each time the profiling data is saved.
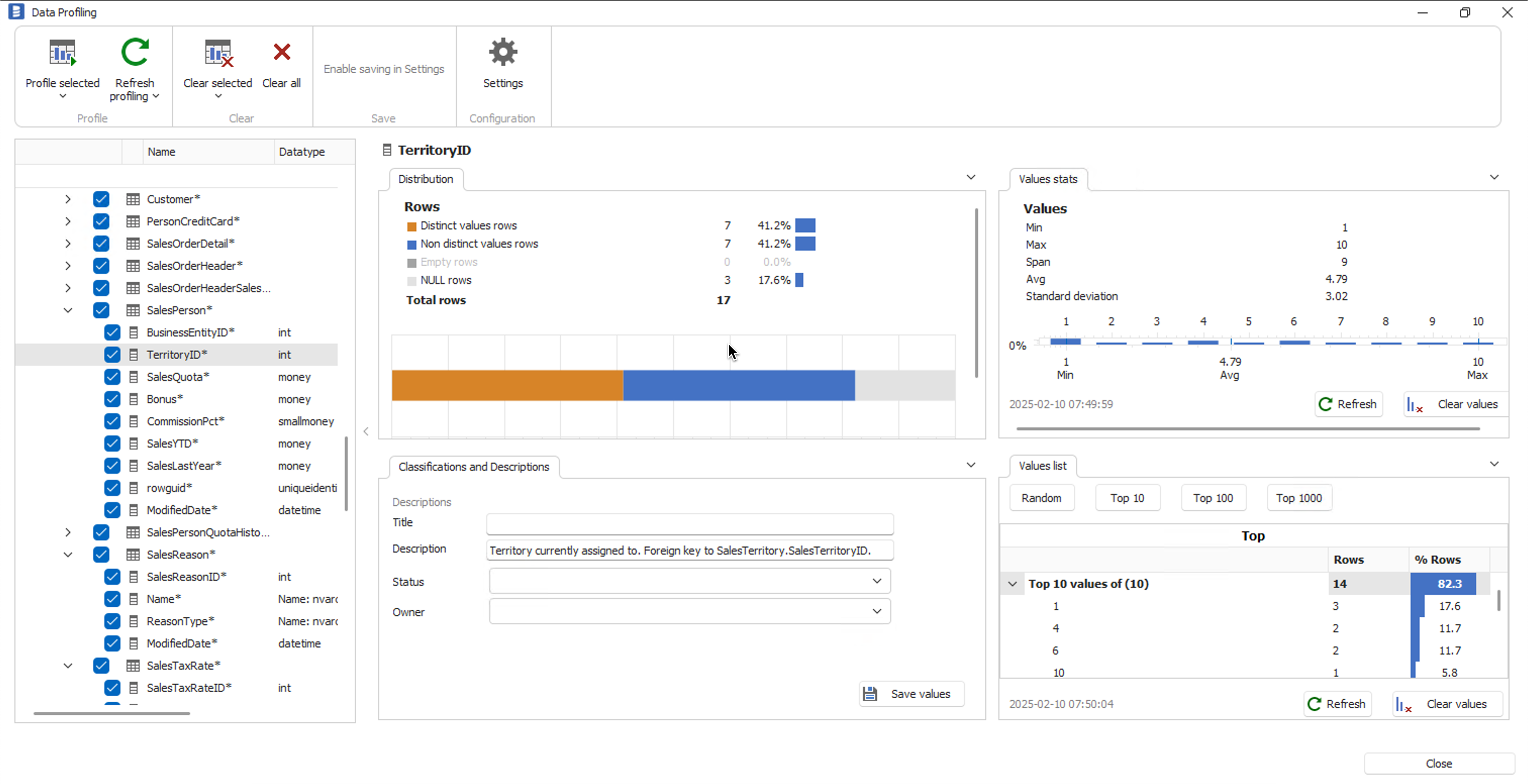
Column distribution
Column distribution analysis categorizes the types of values within a column based on nullability and uniqueness:
Distinct values: Unique entries within the column, such as IDs or order numbers.Non-distinct values: Non-unique and non-empty entries, like first names.Empty: Non-null values that are empty strings.NULL: Entries with null values.
Column values profile
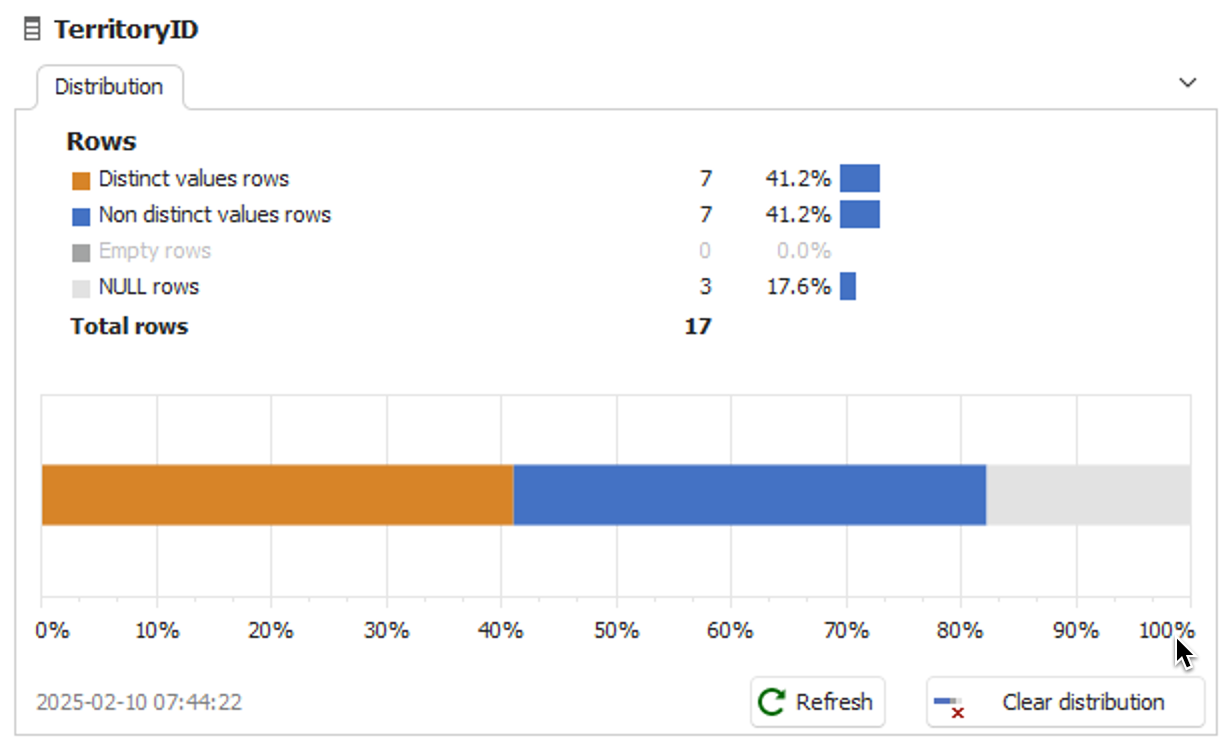
The tool performs basic profiling of numeric values within a column, with results varying based on data type. Metrics include minimum, maximum, average, variance, standard deviation, span, and the number of distinct values. For string data, it calculates metrics like average string length and variance.
| Metric | Numerical | String | Date |
|---|---|---|---|
Min | Minimum value | First alphabetically sorted string | Earliest found date |
Max | Maximum value | Last alphabetically sorted string | Latest found date |
Avg | Average value | Average string length | - |
Variance | Variance counted for values | Variance counted for string length | - |
Standard deviation | Standard deviation for values | Standard deviation for string length | - |
Span | Difference between Max and Min values | - | Difference between Min and Max dates (formatted, e.g., 2 months, 2.5 years) |
Distinct values | Number of distinct values | Number of distinct strings | Number of distinct dates |
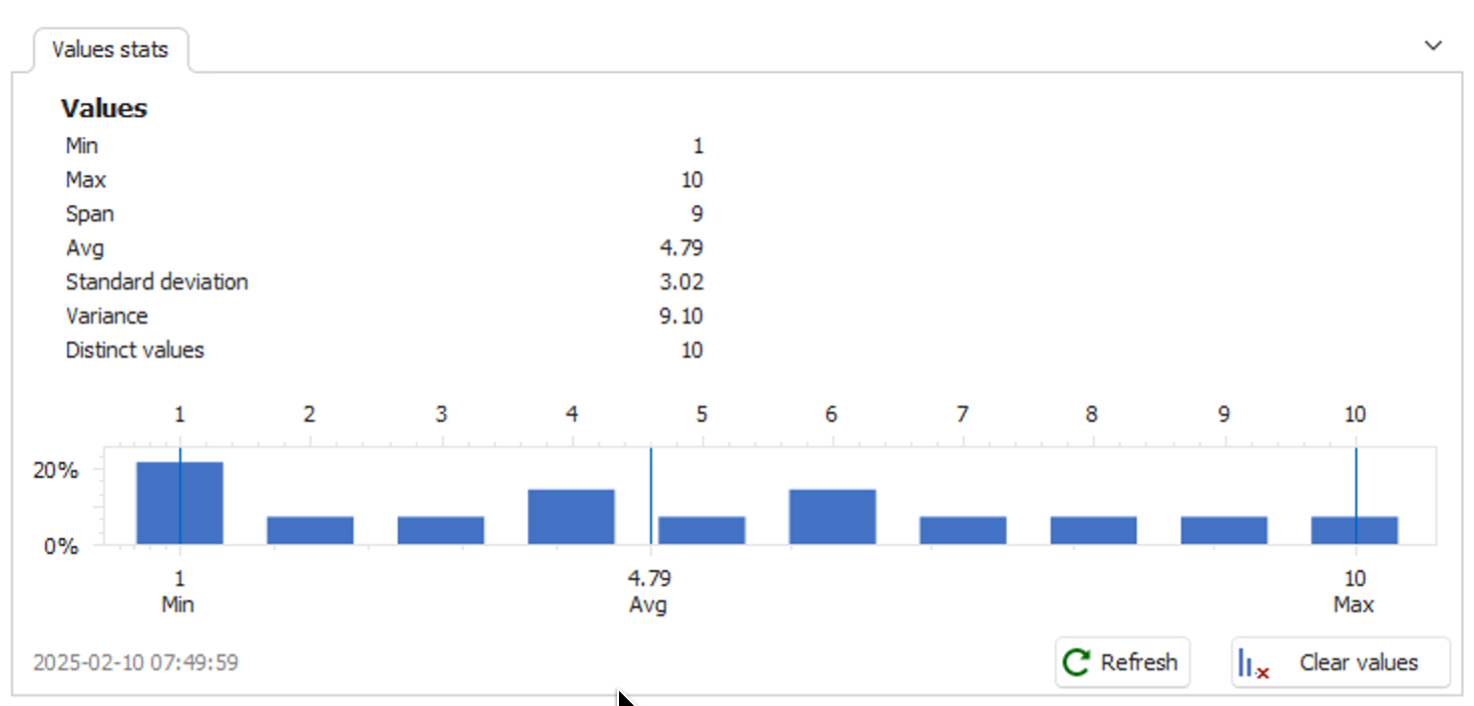
String length profile
String length profiling provides insights into the length of strings within a column, including minimum, maximum, average length, variance, and standard deviation.
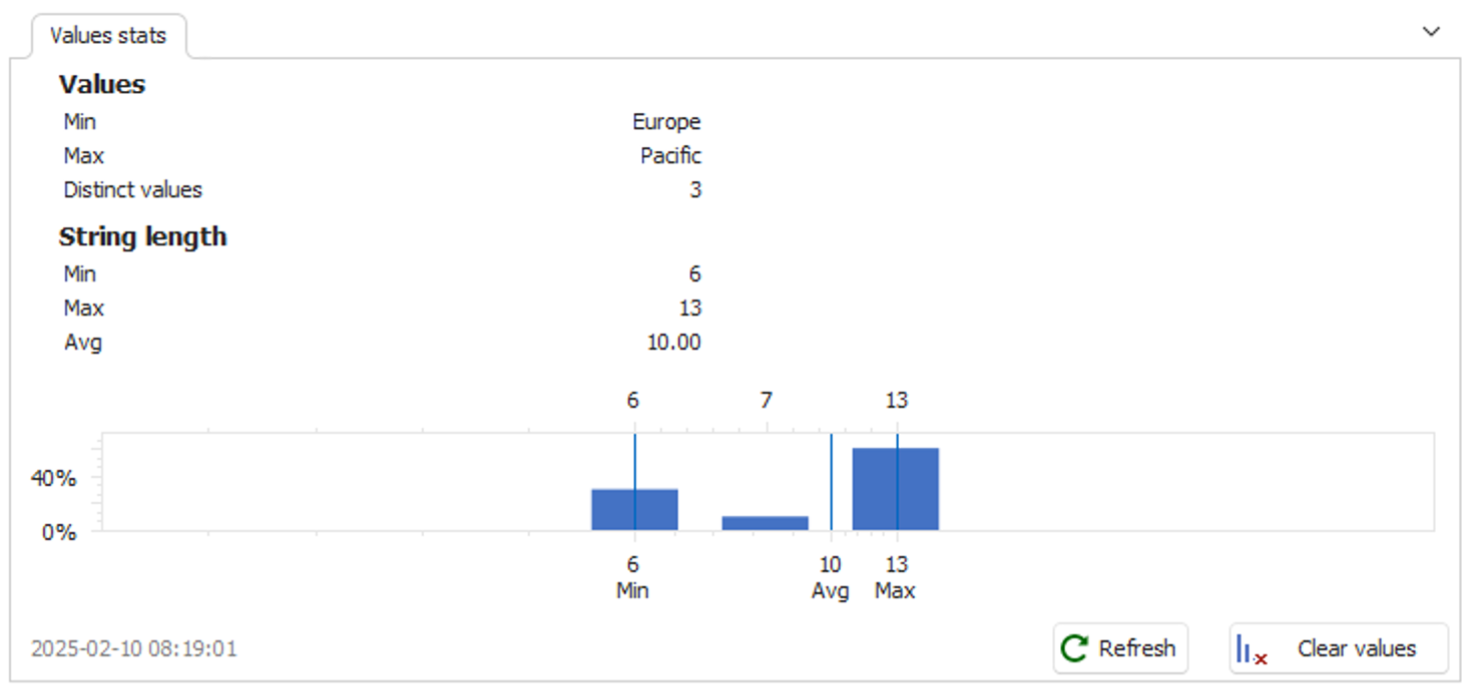
Column top and random values
Data profiling scans columns for the top or random values, with the tool calculating the frequency of each value. It is useful for identifying popular values or sampling unique entries like order numbers.
- Random values
- Top values
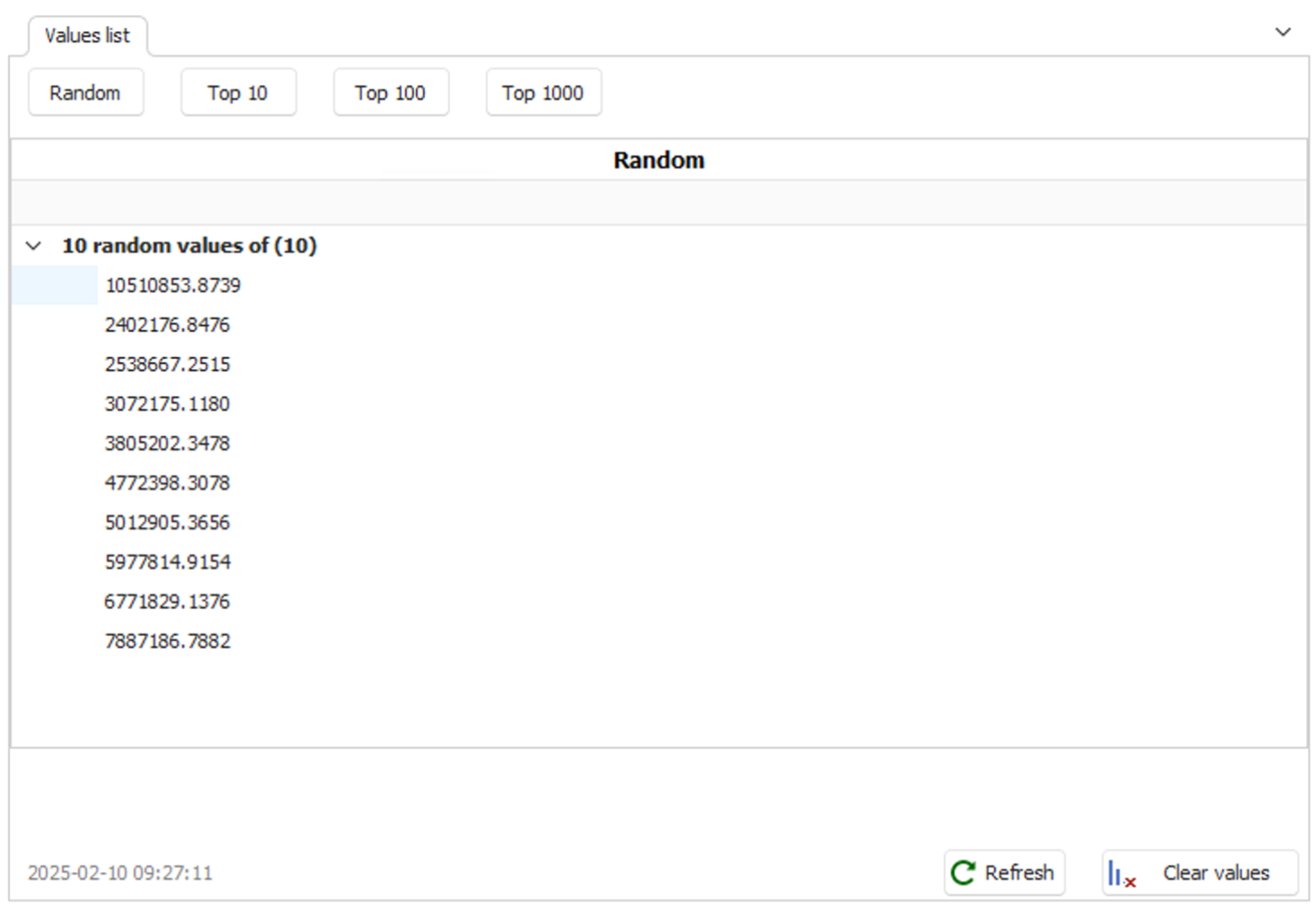
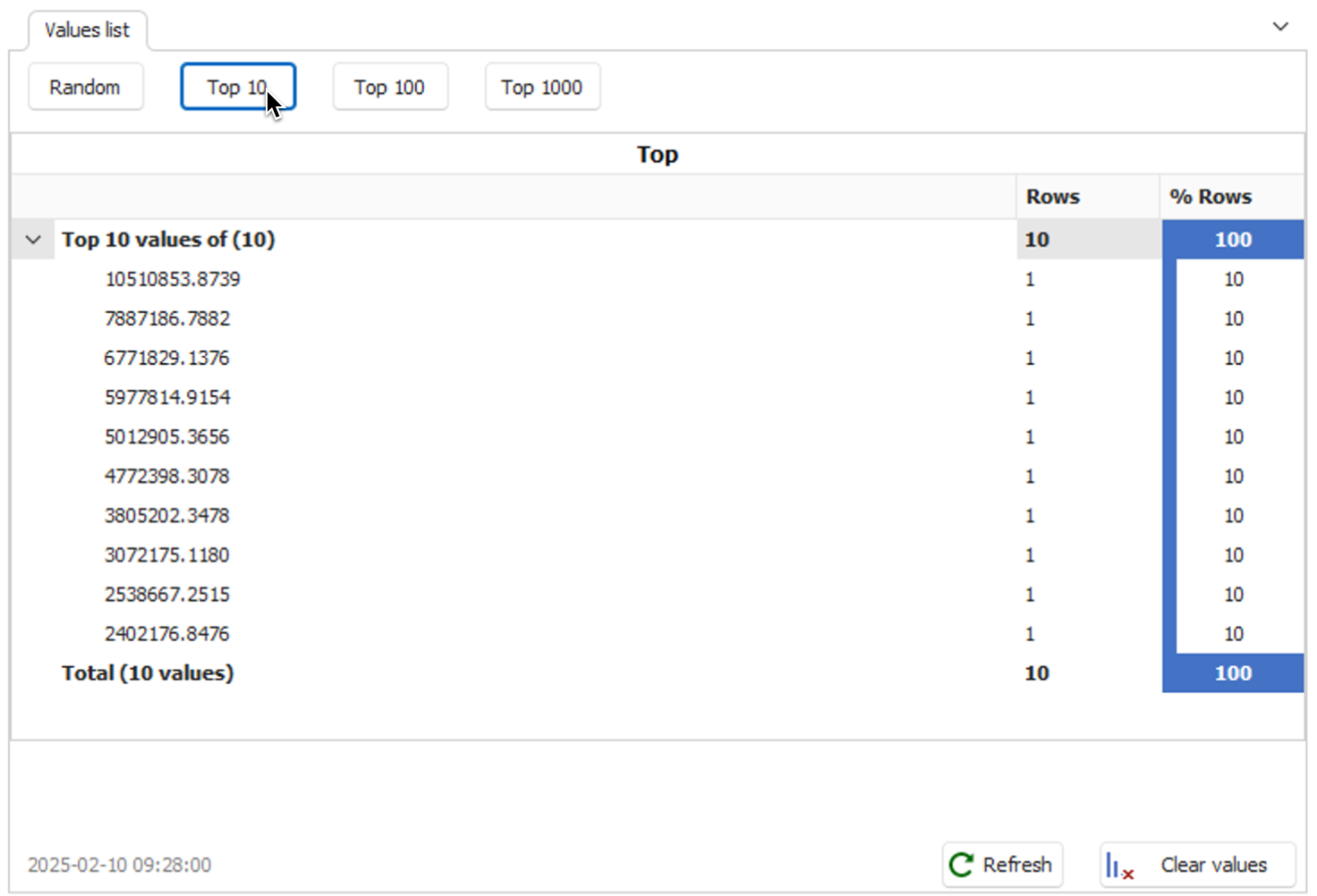
Sample data
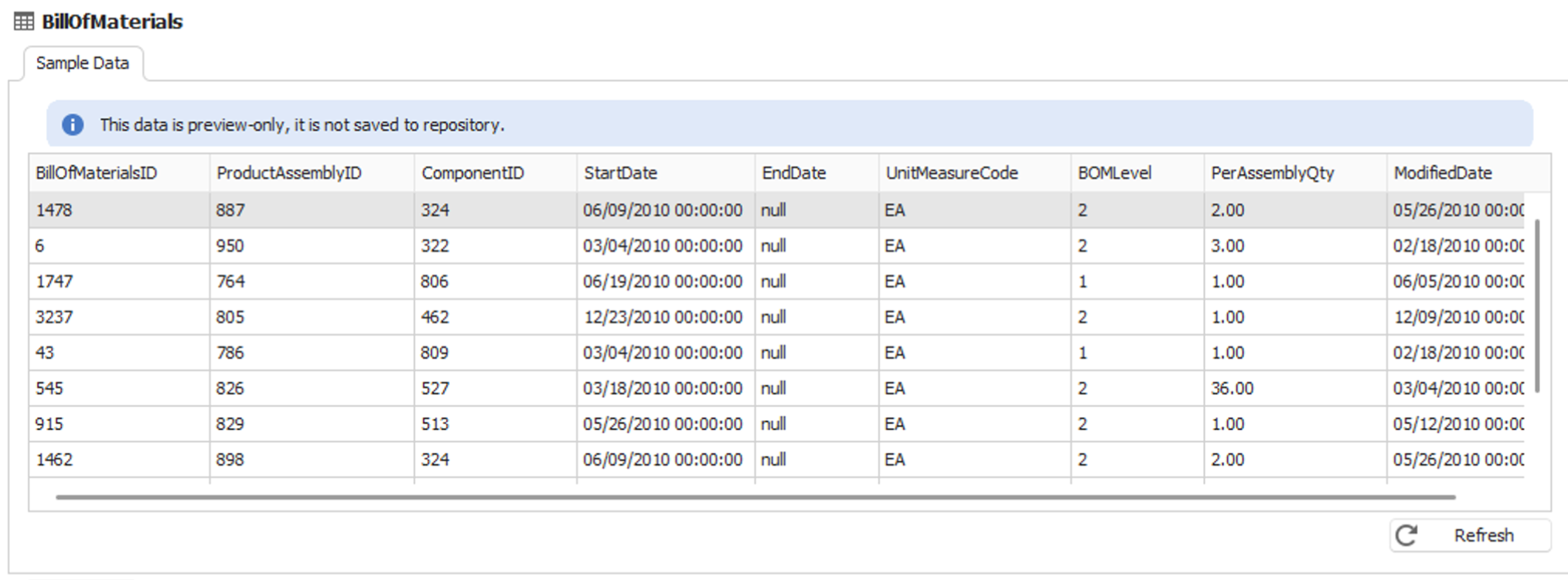
Data Profiling fetches random rows from a table, presenting them in a tabular format for quick review. Dataedo doesn't save this data. This way, it stays temporary and up-to-date.
How profiling works
When you run Data Profiling, Dataedo scans tables and columns to gather statistics and top data. Dataedo calculates these statistics at the database level, which minimizes data transfer.
Once the Profiling is complete, you can view these statistics in Dataedo Desktop.
Save profiled data
Saving profiling data is optional and can be configured according to preferences. By default, saving data is deactivated in Dataedo, you can activate it whenever you need it. When saved, profiling data is stored in the repository alongside data model metadata, such as tables and columns.
Supported sources
The following data sources are supported for data profiling:
 Amazon Athena
Amazon Athena Amazon Aurora MySQLAmazon Aurora PostgreSQL
Amazon Aurora MySQLAmazon Aurora PostgreSQL Amazon Redshift
Amazon Redshift Azure SQL DatabaseAzure SQL Edge
Azure SQL DatabaseAzure SQL Edge Azure Synapse Analytics
Azure Synapse Analytics Databricks
Databricks Google BigQuery
Google BigQuery IBM Db2IBM Db2 LUW
IBM Db2IBM Db2 LUW
 MariaDB
MariaDB Microsoft Fabric - Data Lakehouse
Microsoft Fabric - Data Lakehouse Microsoft Fabric - Data Warehouse
Microsoft Fabric - Data Warehouse MySQL
MySQL OracleOracle e-Business Suite
OracleOracle e-Business Suite Percona Server for MySQL
Percona Server for MySQL PostgreSQL
PostgreSQL SAP Hana
SAP Hana SAP Sybase ASE
SAP Sybase ASE Snowflake
Snowflake
 SQL Server
SQL Server
 Vertica
Vertica
