Metadata Synchronization
Currently, this feature is supported for Databricks and Snowflake connections
Dataedo's Metadata Sync feature allows for two-way synchronization of Data Classification information between your data source and Dataedo. This approach has two benefits. First, it helps reduce work across your organization — all changes made in Dataedo are reflected in your original source, and all changes made in the original data source are projected back onto your Dataedo repository. This ties directly into the second benefit: Dataedo can become a single source of truth for your data's classification. You can use it to manage, review, update, and resolve conflicts in one place, while still ensuring that those changes stay consistent across your sources.
Configuration
Metadata Sync has to be enabled individually for each data source. To do so, head to Connectors > Connections and open the relevant data source. Find the Metadata Sync toggle and enable it.
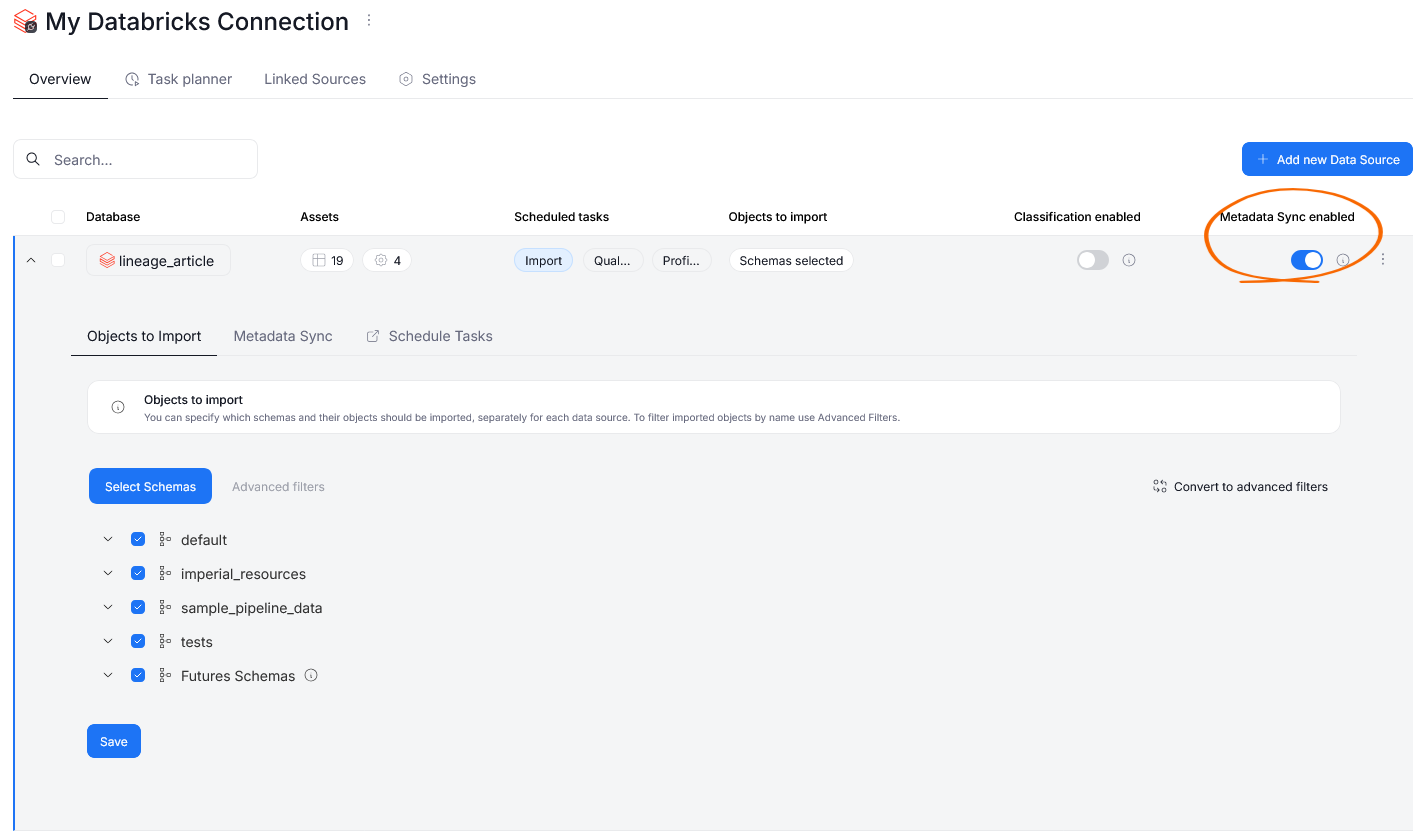
Afterwards, you can open the data source's Metadata Sync section to set up the exact mechanisms governing the synchronization.
Conflict Resolution
The Sync Rules & Conflicts Resolution section allows you to determine how conflicts (situations where there are clashing changes in Dataedo and your original source) will be resolved for each situation. Currently, you can define different behaviors for tables' and views' column Classification; the protocols you can choose are:
-
Manual — conflicts have to be resolved manually by a user in Steward Hub, only once this is done, will the changes be pushed to the Data Source
-
Take Dataedo — conflicts are automatically resolved by overwriting the changes made in your data source using the changes in Dataedo
-
Take Source — conflicts are automatically resolved by propagating the changes made in your data source to Dataedo.
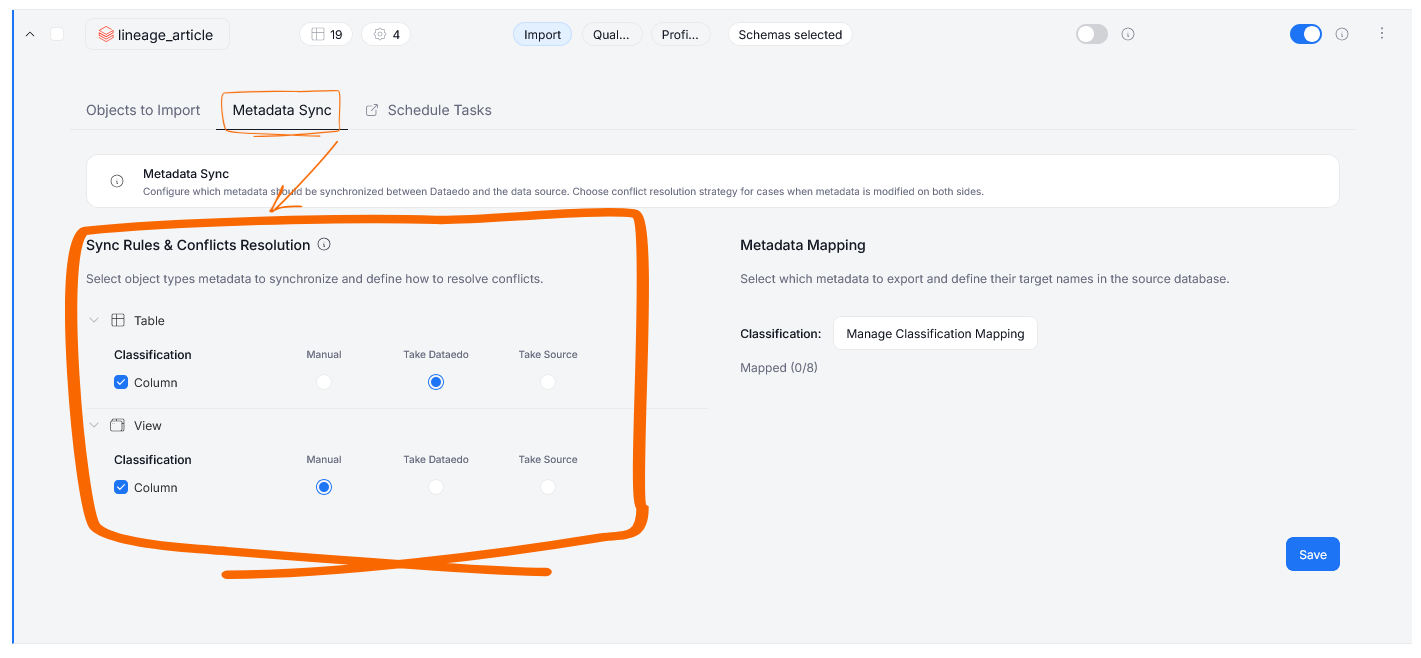
In the future we also plan on expanding the Metadata Sync to object Classification, Custom Fields, and Descriptions — all these categories will also be customizable regarding conflict resolution.
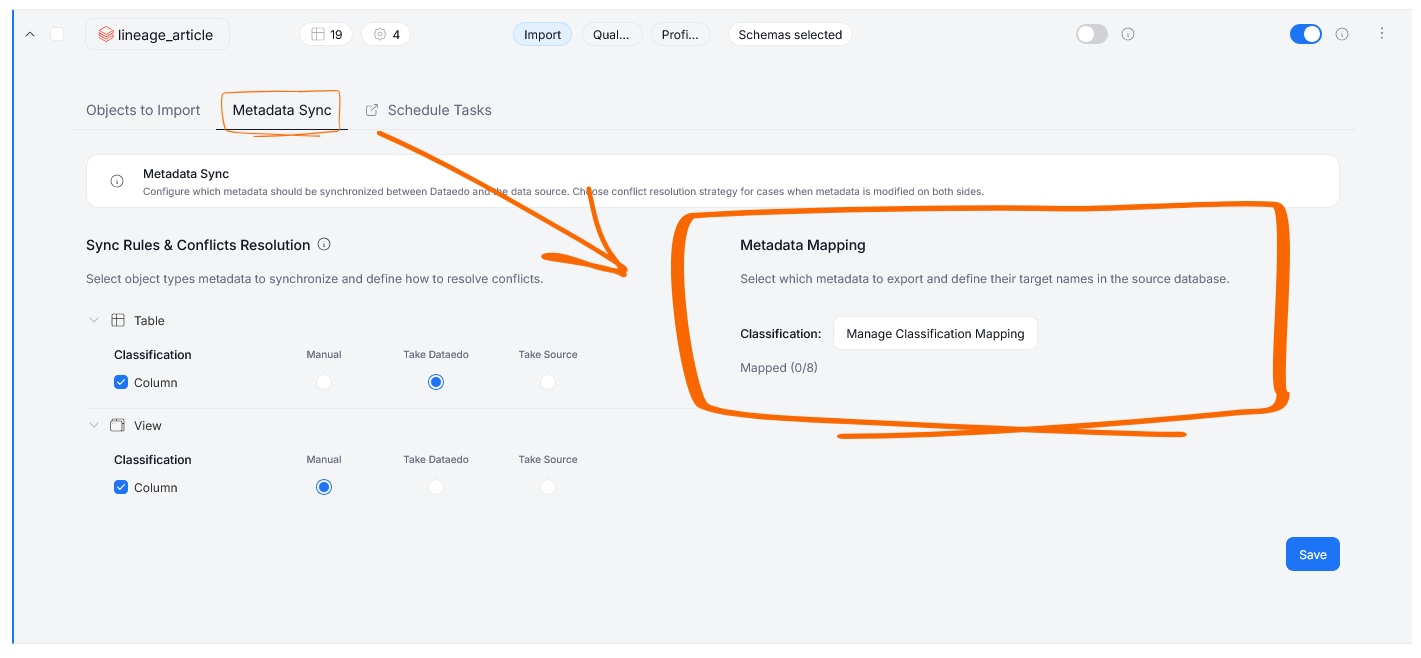
Metadata Mapping
In the Metadata Mapping section, you can map Classifications from your Dataedo repository onto tags and their values in your data source.
When you click the Manage Classification Mapping button, you will access a mapping menu. There you can select which Dataedo Classifications you want to map using checkboxes [A]. For each mapped Classification, you have to provide the corresponding Tag Name [B] in your data source. Make sure the Tag Name exists, and it matches exactly what you input. Finally, you can provide the Tag Values [C] that will correspond to your Classification's sensitivity levels.
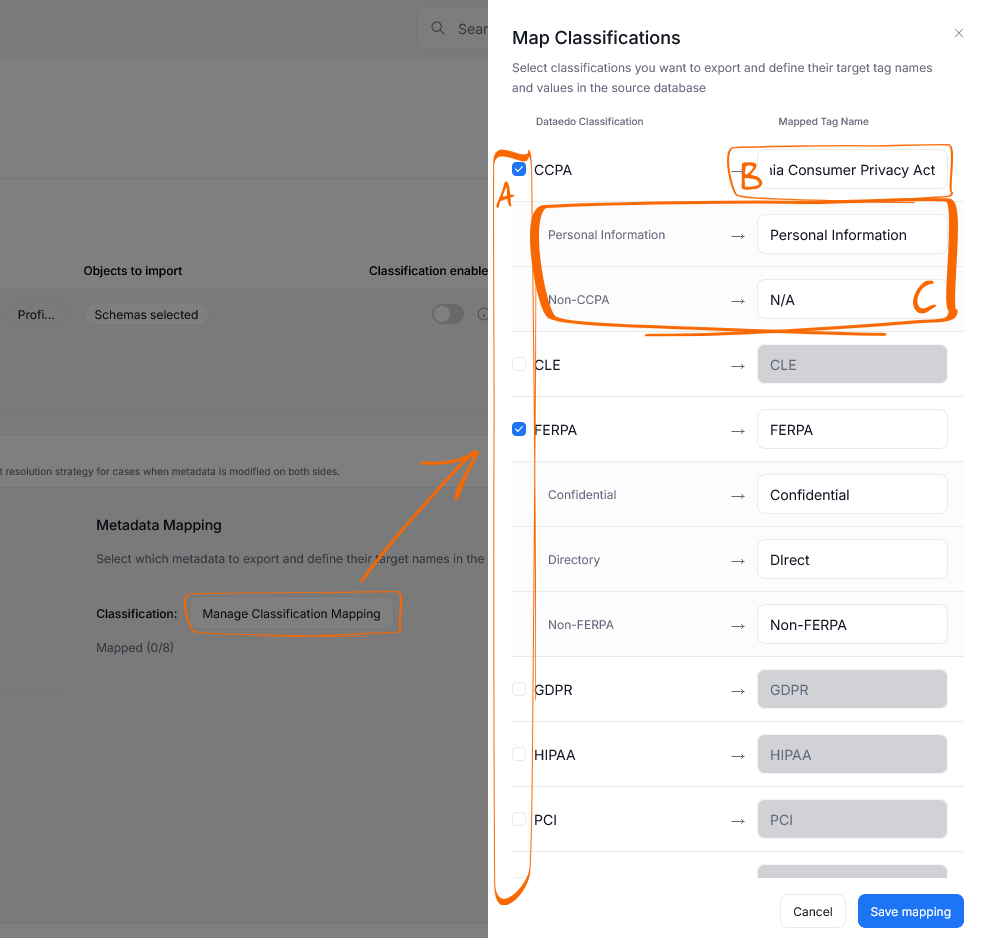
Once you save the configuration, the two-way sync will be enabled and will take effect from the next Metadata (re)import onward.
Import Settings
When editing or scheduling an Import Task, you have the option to additionally define the behavior of a Metadata Sync.
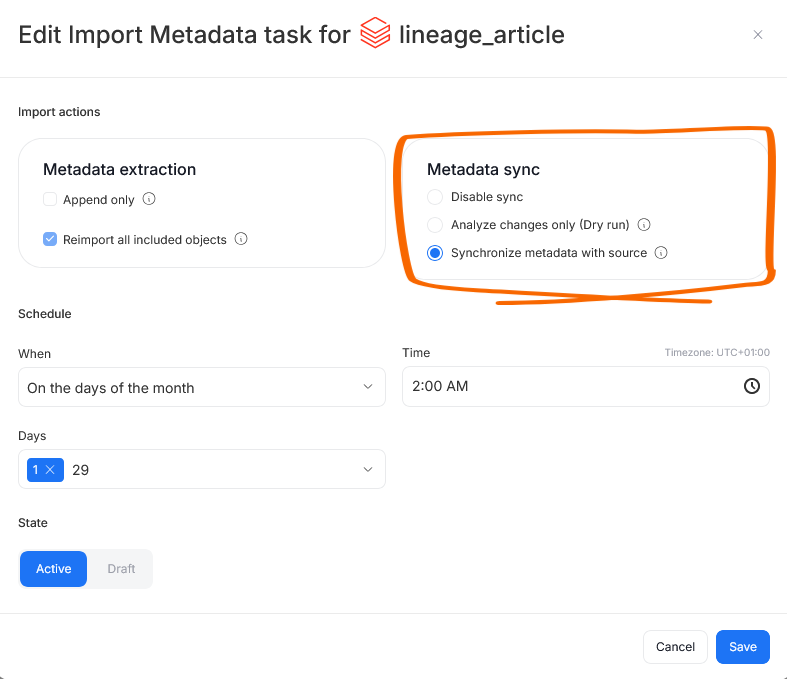
Choosing Disable export prevents any metadata sync-related actions, even if the feature is enabled in the source configuration.
Analyze changes only enables a Dry Run. In Dry Run mode, changes and conflicts between your data source and Dataedo are analyzed and returned as a report within Dataedo, but no changes are pushed to your data source directly. This is a great option for data-sensitive organizations — you still receive a summary of changes that should be propagated to your original data source to match your Dataedo documentation, while preventing any automated modifications at the source. All changes can instead be reviewed and manually applied by your team.
Synchronize metadata with source gives Dataedo permission to push changes to your data source in accordance with the chosen conflict resolution protocol.
How it works
The Metadata Sync process can be broken down into steps.
First, during a Metadata Import, Dataedo checks the current state of tags in the data source and compares:
- tags in the source before import
- classification in Dataedo
- tags in the source after import
This comparison enables a detailed analysis of changes to classification tags and identifies where those changes originated — either in the source or in your Dataedo repository.
The second step takes place immediately after a Metadata Import. Any changes made either in Dataedo or in your data source since the last reimport, as well as the changes kept after using the chosen conflict resolution protocol are gathered and pushed back to your data source and Dataedo, if you chose to synchronize metadata with source.
If Dry Run is configured, however, changes will not be pushed. Instead, a complete report of what would be pushed becomes viewable in history.
History
Each Metadata Import run followed by a Metadata Sync leaves behind an audit log. You can find these in the connection view, under the Sync History tab.
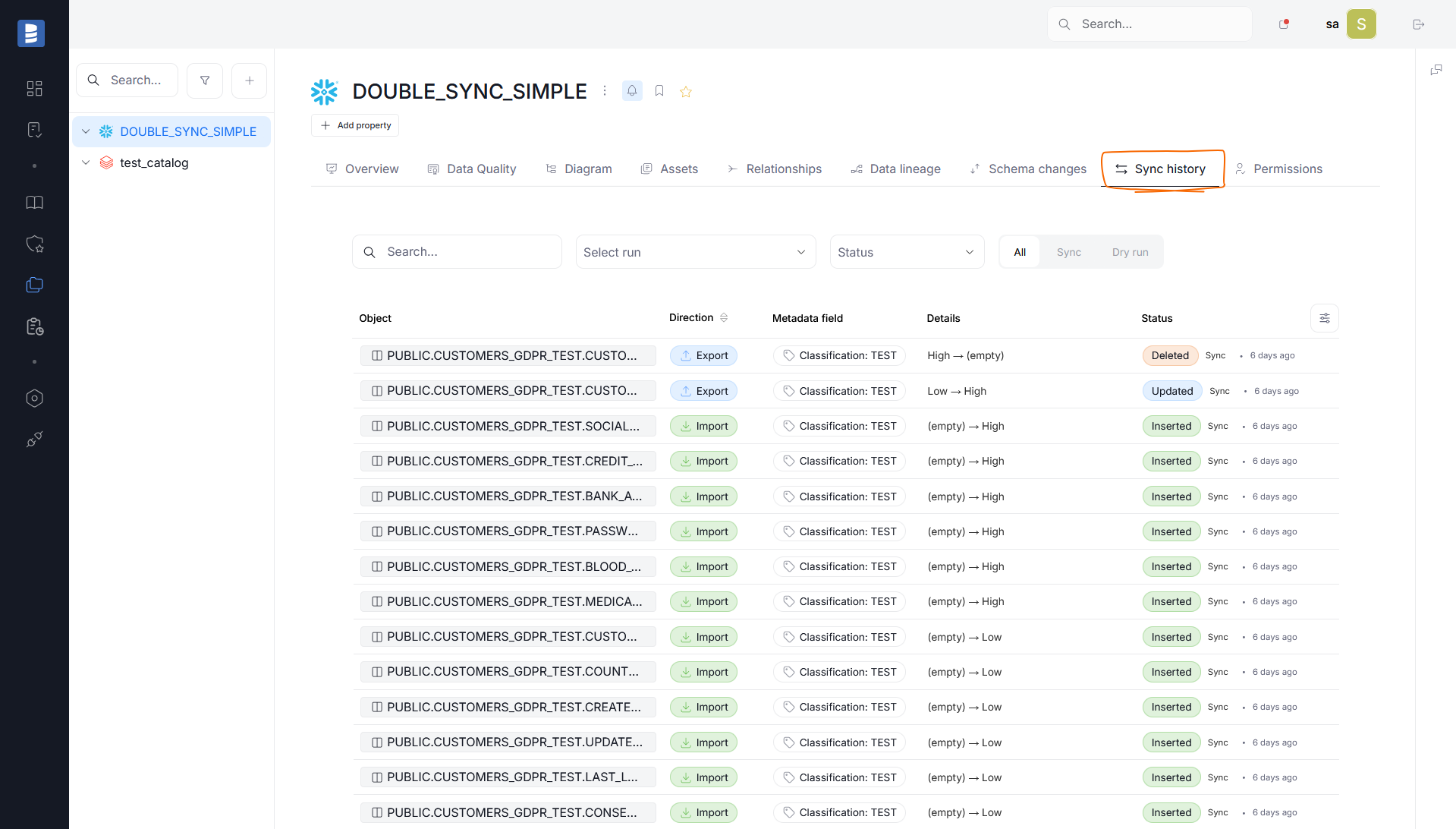
History shows an overview of each Classification change and resolution. You can see which object received the change, what was the update's direction (whether the changed Classification was imported into Dataedo or exported to the source), the details of the change, and the change's type — whether a Classification tag was added, deleted or edited as a result.
By default, history is cumulative, showing an overview of all changes made to the source since the Metadata Sync was enabled. You can, however, filter the results by:
- status
- type (Metadata Synchronization or Dry Run)
- keywords (using the search bar)
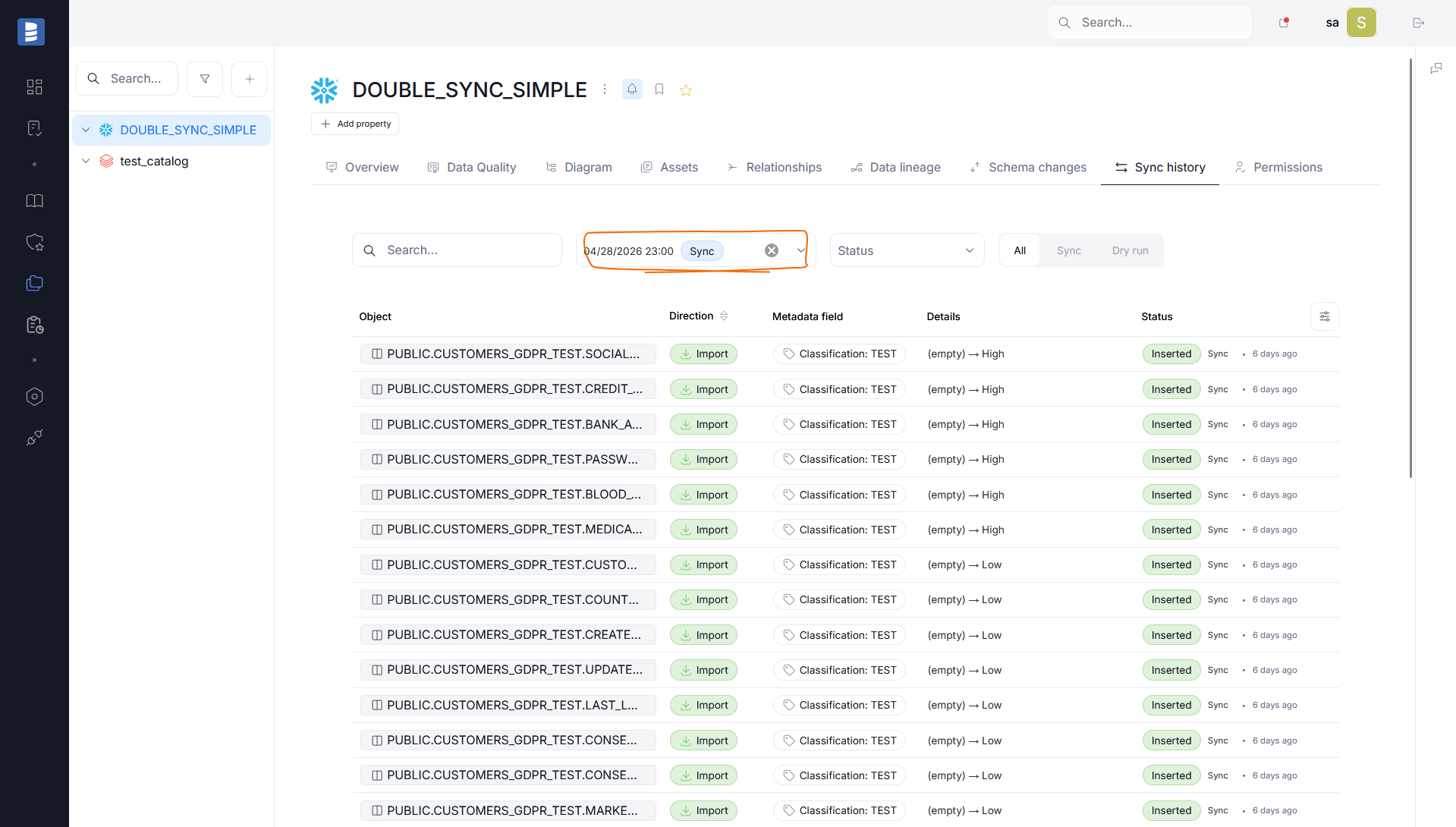
Finally, the Select run field allows you to choose a specific Import Task followed by a Metadata Sync, to see changes that were made only during that particular task.
Steward Hub
If you set the conflict resolution to manual, you will have to resolve conflicts yourself before the Metadata Sync takes place. This can be done using Steward Hub's Metadata Sync module.
Each change is shown as a separate row on a grid. In each row you can:
- see which object has the conflict [A]
- see which metadata field (Classification) is changing [B]
- see what is the sensitivity level set in Dataedo and in your data source [C]
- decide whether the Classification from Dataedo or the data source should be kept [D]
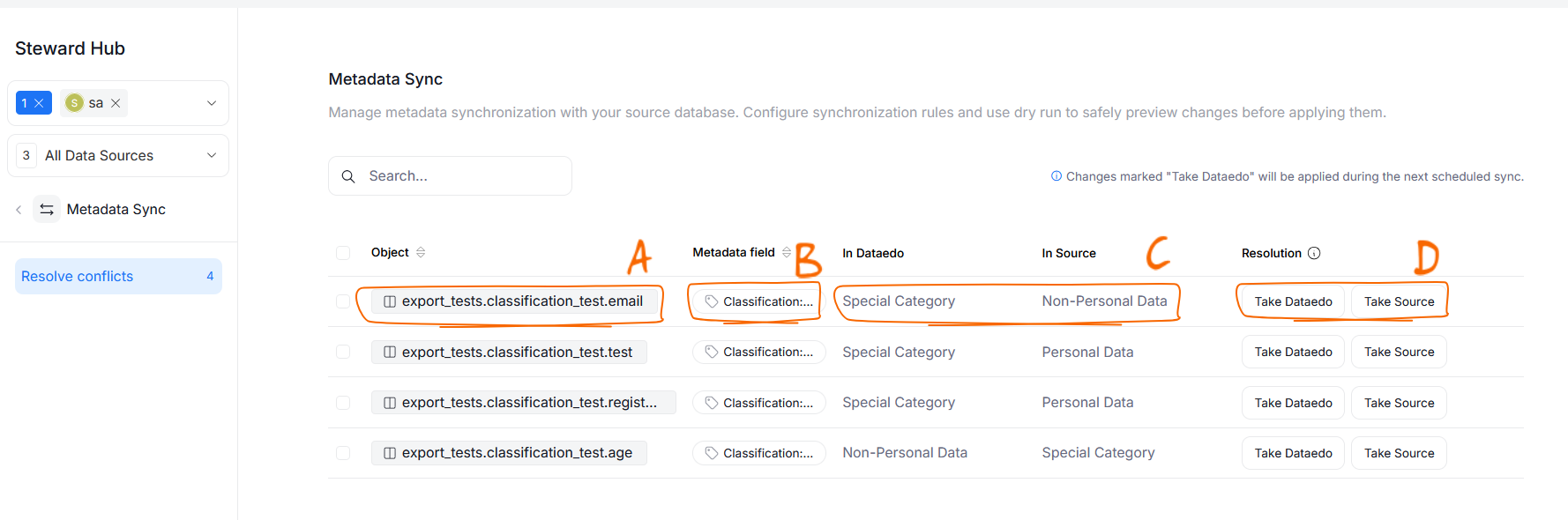
Conflicts resolved as Take Source will be immediately propagated onto Dataedo, while those resolved as Take Dataedo will be pushed to your source only during the next scheduled Metadata Sync.
Technical Specs
Metadata Sync currently supports column-level Classification only.
Executors
After a Metadata Import, classification changes are applied to the source using a connector-specific executor:
| Connector | Mechanism |
|---|---|
| Databricks (Unity Catalog) | SET TAG / UNSET TAG |
| Snowflake | ALTER COLUMN SET TAG |
Tag Targeting
Each connector targets tags using its native tagging model:
| Connector | Tag model |
|---|---|
| Databricks | Unity Catalog tags |
| Snowflake | Tag references |
Sync History Retention
Currently sync history is not pruned automatically — the log grows over time.

